Yunlong (Yolo) Tang
[ Yolo Y. Tang • /ˈjoʊloʊ tɛn / • 芸珑 • she/her/hers ]


I’m a Ph.D. student at the University of Rochester, advised by Prof. Chenliang Xu, working on LMMs/Agents for Video Understanding.
I obtained my B.Eng. from SUSTech in 2023, supervised by Prof. Feng Zheng. I’ve interned at Amazon, ByteDance, and Tencent.
Please feel free to contact me if you’re interested in collaboration!
Selected Research 
* Equal Contribution | † Corresponding Author
-
 Yolo Yunlong Tang, Daiki Shimada, Hang Hua, Chao Huang, Jing Bi, Rogerio Feris, and Chenliang XuarXiv preprint arXiv:2511.17490, 2025
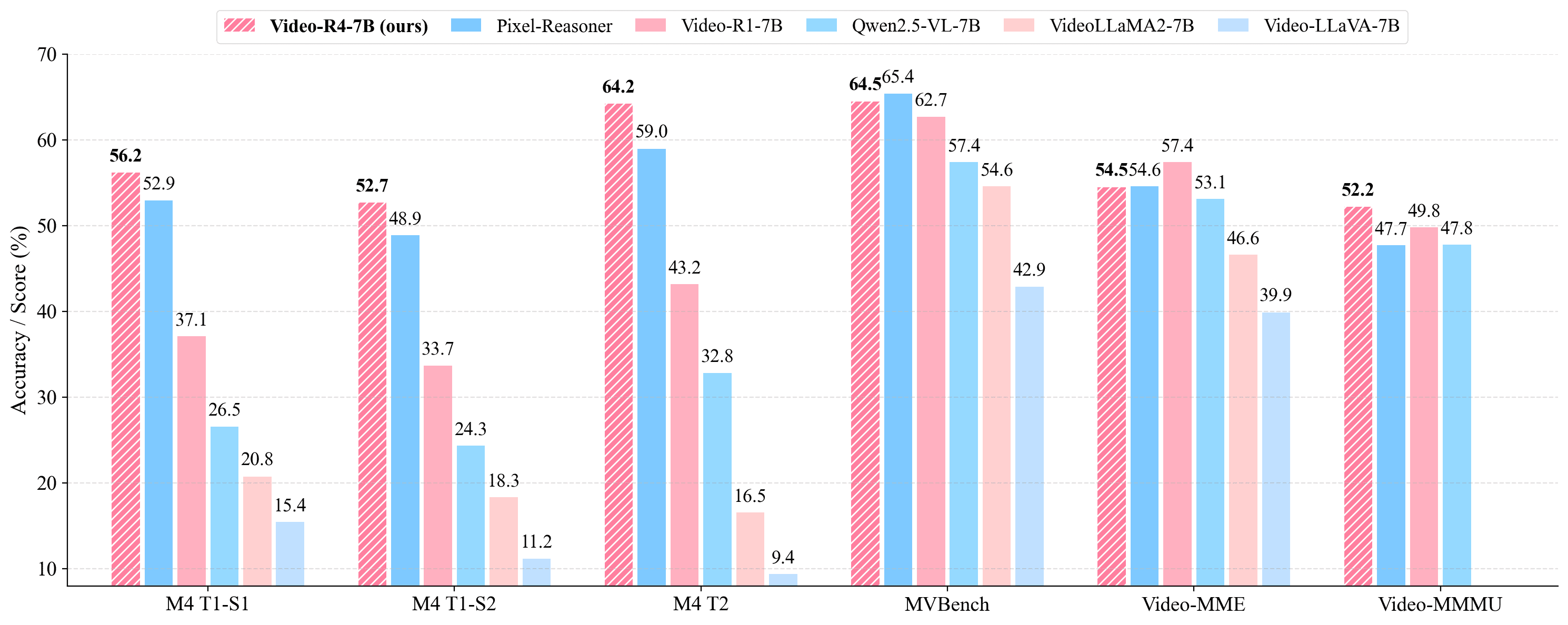
Yolo Yunlong Tang, Daiki Shimada, Hang Hua, Chao Huang, Jing Bi, Rogerio Feris, and Chenliang XuarXiv preprint arXiv:2511.17490, 2025Understanding text-rich videos requires reading small, transient textual cues that often demand repeated inspection. Yet most video QA models rely on single-pass perception over fixed frames, leading to hallucinations and failures on fine-grained evidence. Inspired by how humans pause, zoom, and re-read critical regions, we introduce Video-R4 (Reinforcing Text-Rich Video Reasoning with Visual Rumination), a video reasoning LMM that performs visual rumination: iteratively selecting frames, zooming into informative regions, re-encoding retrieved pixels, and updating its reasoning state. We construct two datasets with executable rumination trajectories: Video-R4-CoT-17k for supervised practice and Video-R4-RL-30k for reinforcement learning. We propose a multi-stage rumination learning framework that progressively finetunes a 7B LMM to learn atomic and mixing visual operations via SFT and GRPO-based RL. Video-R4-7B achieves state-of-the-art results on M4-ViteVQA and further generalizes to multi-page document QA, slides QA, and generic video QA, demonstrating that iterative rumination is an effective paradigm for pixel-grounded multimodal reasoning. For more information, readers are recommended to visit the repository at https://github.com/yunlong10/Video-R4.
@article{tang2025videor4, title = {Video-R4: Reinforcing Text-Rich Video Reasoning with Visual Rumination}, author = {Tang, Yolo Yunlong and Shimada, Daiki and Hua, Hang and Huang, Chao and Bi, Jing and Feris, Rogerio and Xu, Chenliang}, journal = {arXiv preprint arXiv:2511.17490}, year = {2025}, } -
 Yolo Yunlong Tang, Jing Bi, Pinxin Liu, Zhenyu Pan, Zhangyun Tan, Qianxiang Shen, Jiani Liu, Hang Hua, Junjia Guo, Yunzhong Xiao, and 17 more authorsarXiv preprint arXiv:2510.05034, 2025
Yolo Yunlong Tang, Jing Bi, Pinxin Liu, Zhenyu Pan, Zhangyun Tan, Qianxiang Shen, Jiani Liu, Hang Hua, Junjia Guo, Yunzhong Xiao, and 17 more authorsarXiv preprint arXiv:2510.05034, 2025Video understanding represents the most challenging frontier in computer vision. It requires models to reason about complex spatiotemporal relationships, long-term dependencies, and multimodal evidence. The recent emergence of Video-Large Multimodal Models (Video-LMMs), which integrate visual encoders with powerful decoder-based language models, has demonstrated remarkable capabilities in video understanding tasks. However, the critical phase that transforms these models from basic perception systems into sophisticated reasoning engines, post-training, remains fragmented across the literature. This survey provides the first comprehensive examination of post-training methodologies for Video-LMMs, encompassing three fundamental pillars: supervised fine-tuning (SFT) with chain-of-thought, reinforcement learning (RL) from verifiable objectives, and test-time scaling (TTS) through enhanced inference computation. We present a structured taxonomy that clarifies the roles, interconnections, and video-specific adaptations of these techniques, addressing unique challenges such as temporal localization, spatiotemporal grounding, long video efficiency, and multimodal evidence integration. Through systematic analysis of representative methods, we synthesize key design principles, insights, and evaluation protocols while identifying critical open challenges in reward design, scalability, and cost-performance optimization. We further curate essential benchmarks, datasets, and metrics to facilitate rigorous assessment of post-training effectiveness. This survey aims to provide researchers and practitioners with a unified framework for advancing Video-LMM capabilities. Additional resources and updates are maintained at: https://arxiv.org/abs/2510.05034
@article{tang2025videolmm_posttraining, title = {Video-LMM Post-Training: A Deep Dive into Video Reasoning with Large Multimodal Models 🔥🔥🔥}, author = {Tang, Yolo Yunlong and Bi, Jing and Liu, Pinxin and Pan, Zhenyu and Tan, Zhangyun and Shen, Qianxiang and Liu, Jiani and Hua, Hang and Guo, Junjia and Xiao, Yunzhong and Huang, Chao and Wang, Zhiyuan and Liang, Susan and Liu, Xinyi and Song, Yizhi and Huang, Junhua and Zhong, Jia-Xing and Li, Bozheng and Qi, Daiqing and Zeng, Ziyun and Vosoughi, Ali and Song, Luchuan and Zhang, Zeliang and Shimada, Daiki and Liu, Han and Luo, Jiebo and Xu, Chenliang}, journal = {arXiv preprint arXiv:2510.05034}, year = {2025}, } - NeurIPS
 Yunlong Tang, Pinxin Liu, Zhangyun Tan, Mingqian Feng, Rui Mao, Chao Huang, Jing Bi, Yunzhong Xiao, Susan Liang, Hang Hua, and 4 more authorsThe Thirty-ninth Annual Conference on Neural Information Processing Systems (NeurIPS) Datasets and Benchmarks Track, 2025
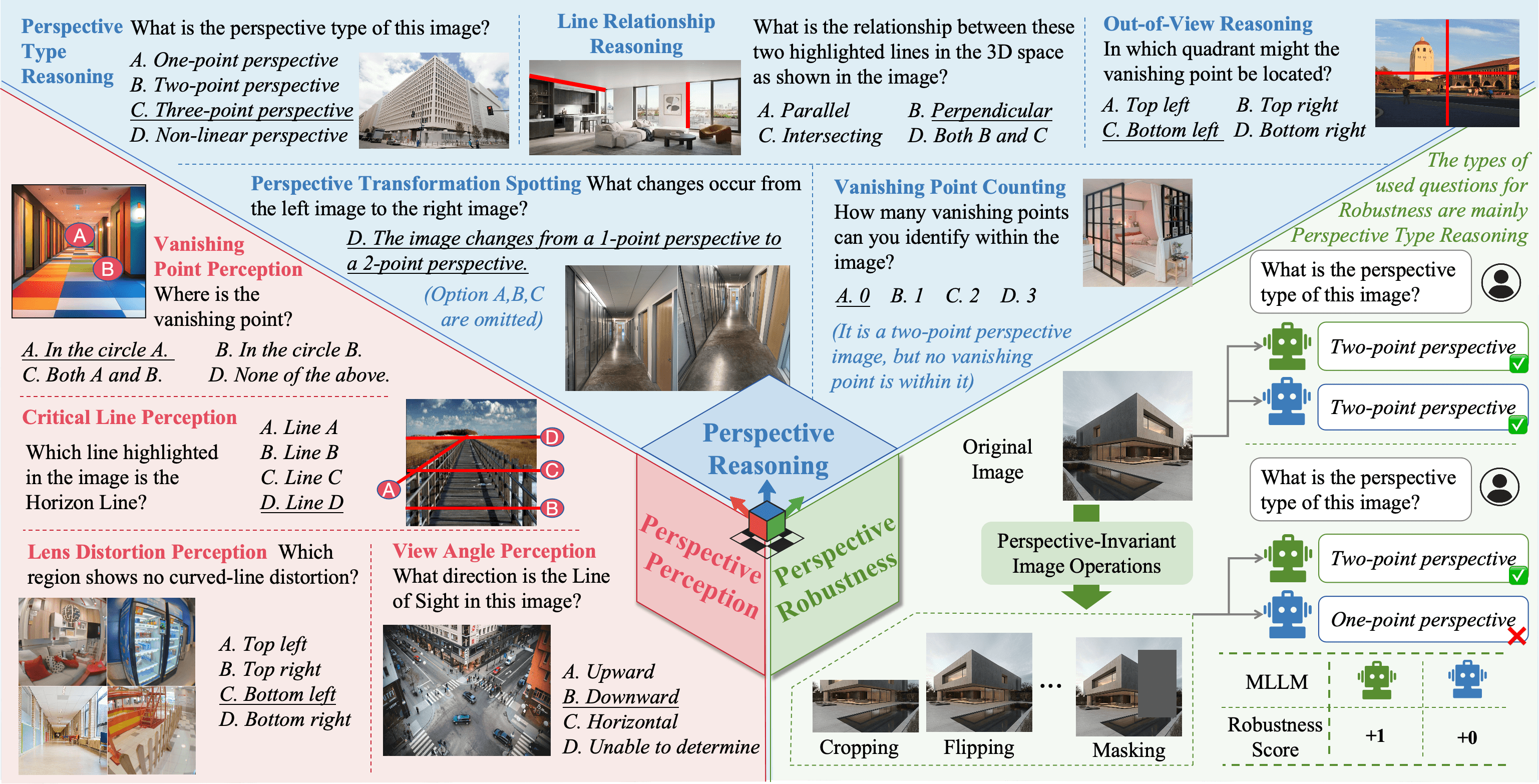
Yunlong Tang, Pinxin Liu, Zhangyun Tan, Mingqian Feng, Rui Mao, Chao Huang, Jing Bi, Yunzhong Xiao, Susan Liang, Hang Hua, and 4 more authorsThe Thirty-ninth Annual Conference on Neural Information Processing Systems (NeurIPS) Datasets and Benchmarks Track, 2025@article{tang2025mmperspective, title = {MMPerspective: Do MLLMs Understand Perspective? A Comprehensive Benchmark for Perspective Perception, Reasoning, and Robustness}, author = {Tang, Yunlong and Liu, Pinxin and Tan, Zhangyun and Feng, Mingqian and Mao, Rui and Huang, Chao and Bi, Jing and Xiao, Yunzhong and Liang, Susan and Hua, Hang and Vosoughi, Ali and Song, Luchuan and Zhang, Zeliang and Xu, Chenliang}, journal = {The Thirty-ninth Annual Conference on Neural Information Processing Systems (NeurIPS) Datasets and Benchmarks Track}, year = {2025}, } - TCSVT
 Yunlong Tang, Jing Bi, Siting Xu, Luchuan Song, Susan Liang, Teng Wang, Daoan Zhang, Jie An, Jingyang Lin, Rongyi Zhu, and 10 more authorsIEEE Transactions on Circuits and Systems for Video Technology (TCSVT), 2025
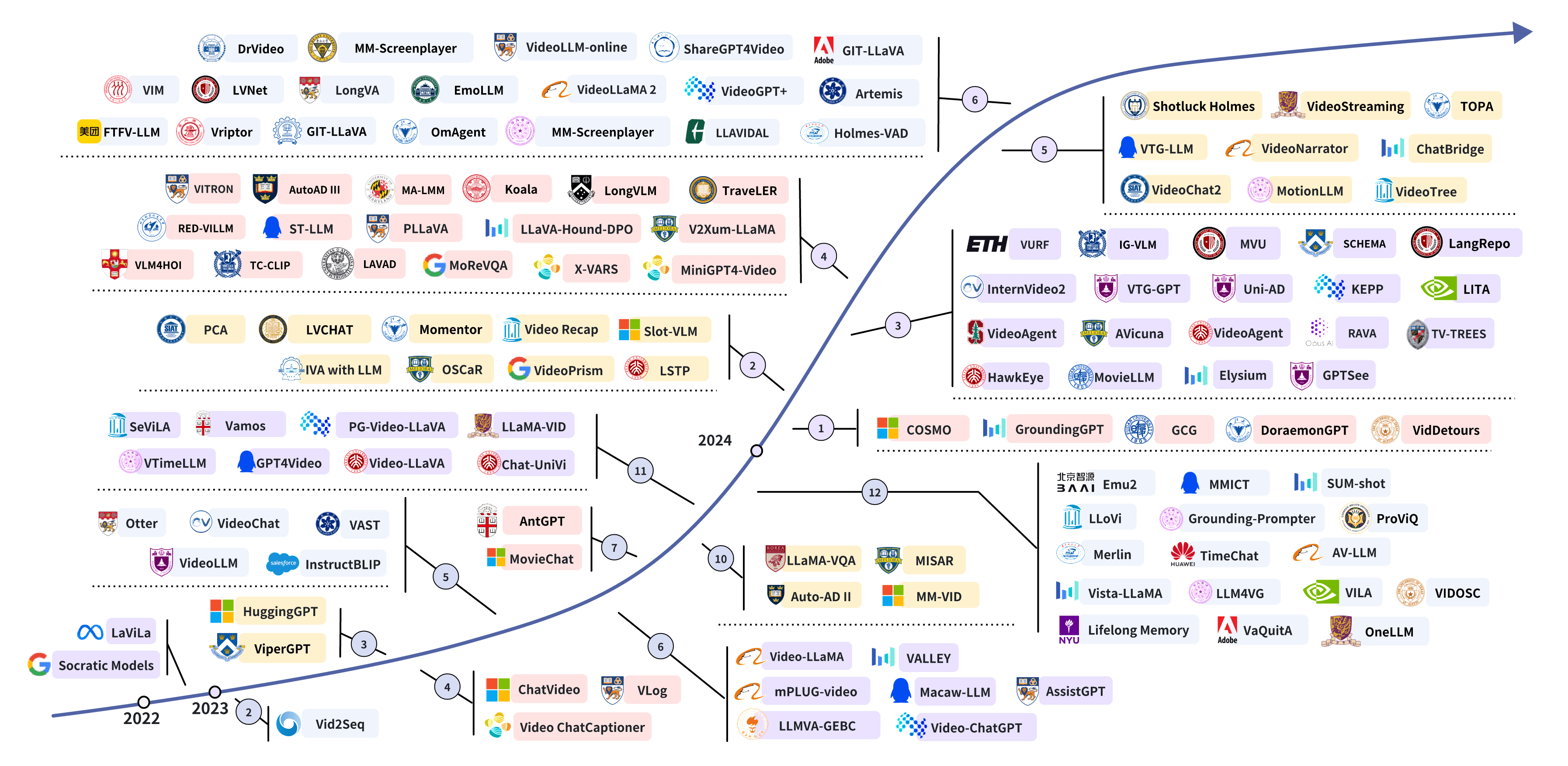
Yunlong Tang, Jing Bi, Siting Xu, Luchuan Song, Susan Liang, Teng Wang, Daoan Zhang, Jie An, Jingyang Lin, Rongyi Zhu, and 10 more authorsIEEE Transactions on Circuits and Systems for Video Technology (TCSVT), 2025With the burgeoning growth of online video platforms and the escalating volume of video content, the demand for proficient video understanding tools has intensified markedly. Given the remarkable capabilities of large language models (LLMs) in language and multimodal tasks, this survey provides a detailed overview of recent advancements in video understanding that harness the power of LLMs (Vid-LLMs). The emergent capabilities of Vid-LLMs are surprisingly advanced, particularly their ability for open-ended multi-granularity (general, temporal, and spatiotemporal) reasoning combined with commonsense knowledge, suggesting a promising path for future video understanding. We examine the unique characteristics and capabilities of Vid-LLMs, categorizing the approaches into three main types: Video Analyzer x LLM, Video Embedder x LLM, and (Analyzer + Embedder) x LLM. Furthermore, we identify five sub-types based on the functions of LLMs in Vid-LLMs: LLM as Summarizer, LLM as Manager, LLM as Text Decoder, LLM as Regressor, and LLM as Hidden Layer. Furthermore, this survey presents a comprehensive study of the tasks, datasets, benchmarks, and evaluation methodologies for Vid-LLMs. Additionally, it explores the expansive applications of Vid-LLMs across various domains, highlighting their remarkable scalability and versatility in real-world video understanding challenges. Finally, it summarizes the limitations of existing Vid-LLMs and outlines directions for future research. For more information, readers are recommended to visit the repository at https://github.com/yunlong10/awesome-llms-for-video-understanding.
@article{vidllmsurvey, title = {Video Understanding with Large Language Models: A Survey 🔥🔥🔥}, author = {Tang, Yunlong and Bi, Jing and Xu, Siting and Song, Luchuan and Liang, Susan and Wang, Teng and Zhang, Daoan and An, Jie and Lin, Jingyang and Zhu, Rongyi and Vosoughi, Ali and Huang, Chao and Zhang, Zeliang and Liu, Pinxin and Feng, Mingqian and Zheng, Feng and Zhang, Jianguo and Luo, Ping and Luo, Jiebo and Xu, Chenliang}, journal = {IEEE Transactions on Circuits and Systems for Video Technology (TCSVT)}, year = {2025}, publisher = {IEEE}, } - CVPR
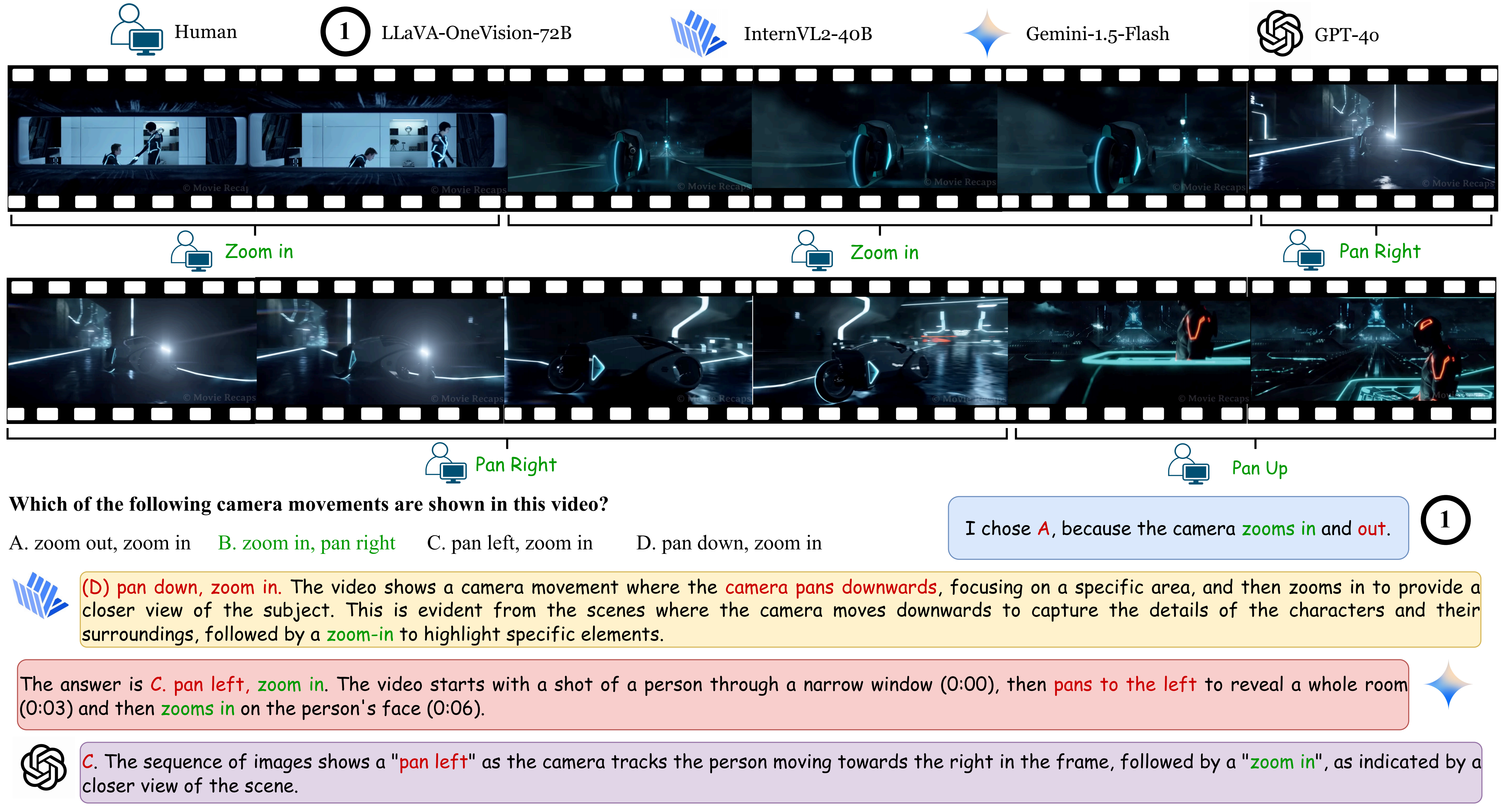 Yunlong Tang*, Junjia Guo*, Hang Hua, Susan Liang, Mingqian Feng, Xinyang Li, Rui Mao, Chao Huang, Jing Bi, Zeliang Zhang, and 2 more authorsIn Proceedings of the Computer Vision and Pattern Recognition Conference (CVPR), 2025
Yunlong Tang*, Junjia Guo*, Hang Hua, Susan Liang, Mingqian Feng, Xinyang Li, Rui Mao, Chao Huang, Jing Bi, Zeliang Zhang, and 2 more authorsIn Proceedings of the Computer Vision and Pattern Recognition Conference (CVPR), 2025@inproceedings{tang2024vidcompostion, title = {VidComposition: Can MLLMs Analyze Compositions in Compiled Videos?}, author = {Tang, Yunlong and Guo, Junjia and Hua, Hang and Liang, Susan and Feng, Mingqian and Li, Xinyang and Mao, Rui and Huang, Chao and Bi, Jing and Zhang, Zeliang and Fazli, Pooyan and Xu, Chenliang}, booktitle = {Proceedings of the Computer Vision and Pattern Recognition Conference (CVPR)}, year = {2025}, pages = {8490-8500}, } - AAAI
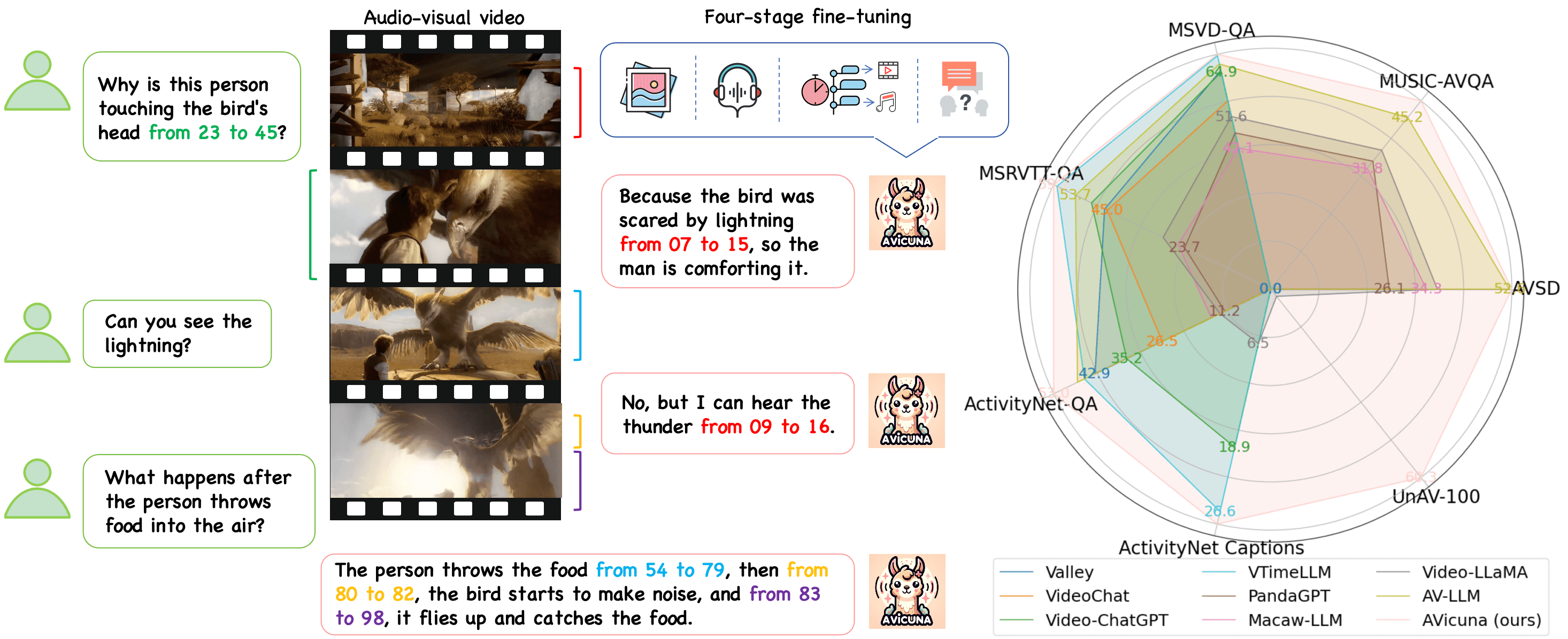 Yunlong Tang, Daiki Shimada, Jing Bi, Mingqian Feng, Hang Hua, and Chenliang Xu†In Proceedings of the AAAI Conference on Artificial Intelligence (AAAI), 2025
Yunlong Tang, Daiki Shimada, Jing Bi, Mingqian Feng, Hang Hua, and Chenliang Xu†In Proceedings of the AAAI Conference on Artificial Intelligence (AAAI), 2025Large language models (LLMs) have demonstrated remarkable capabilities in natural language and multimodal domains. By fine-tuning multimodal LLMs with temporal annotations from well-annotated datasets, e.g., dense video captioning datasets, their temporal understanding capacity in video-language tasks can be obtained. However, there is a notable lack of untrimmed audio-visual video datasets with precise temporal annotations for events. This deficiency hinders LLMs from learning the alignment between time, audio-visual events, and text tokens, thus impairing their ability to localize audio-visual events in videos temporally. To address this gap, we introduce PU-VALOR, a comprehensive audio-visual dataset comprising over 114,000 pseudo-untrimmed videos with detailed temporal annotations. PU-VALOR is derived from the large-scale but coarse-annotated audio-visual dataset VALOR, through a subtle method involving event-based video clustering, random temporal scaling, and permutation. By fine-tuning a multimodal LLM on PU-VALOR, we developed AVicuna, a model capable of aligning audio-visual events with temporal intervals and corresponding text tokens. AVicuna excels in temporal localization and time-aware dialogue capabilities. Our experiments demonstrate that AVicuna effectively handles temporal understanding in audio-visual videos and achieves state-of-the-art performance on open-ended video QA, audio-visual QA, and audio-visual event dense localization tasks.
@inproceedings{tang2024avicuna, title = {Empowering LLMs with Pseudo-Untrimmed Videos for Audio-Visual Temporal Understanding}, author = {Tang, Yunlong and Shimada, Daiki and Bi, Jing and Feng, Mingqian and Hua, Hang and Xu, Chenliang}, booktitle = {Proceedings of the AAAI Conference on Artificial Intelligence (AAAI)}, volume = {39}, number = {7}, pages = {7293-7301}, year = {2025}, doi = {10.1609/aaai.v39i7.32784}, } - AAAI
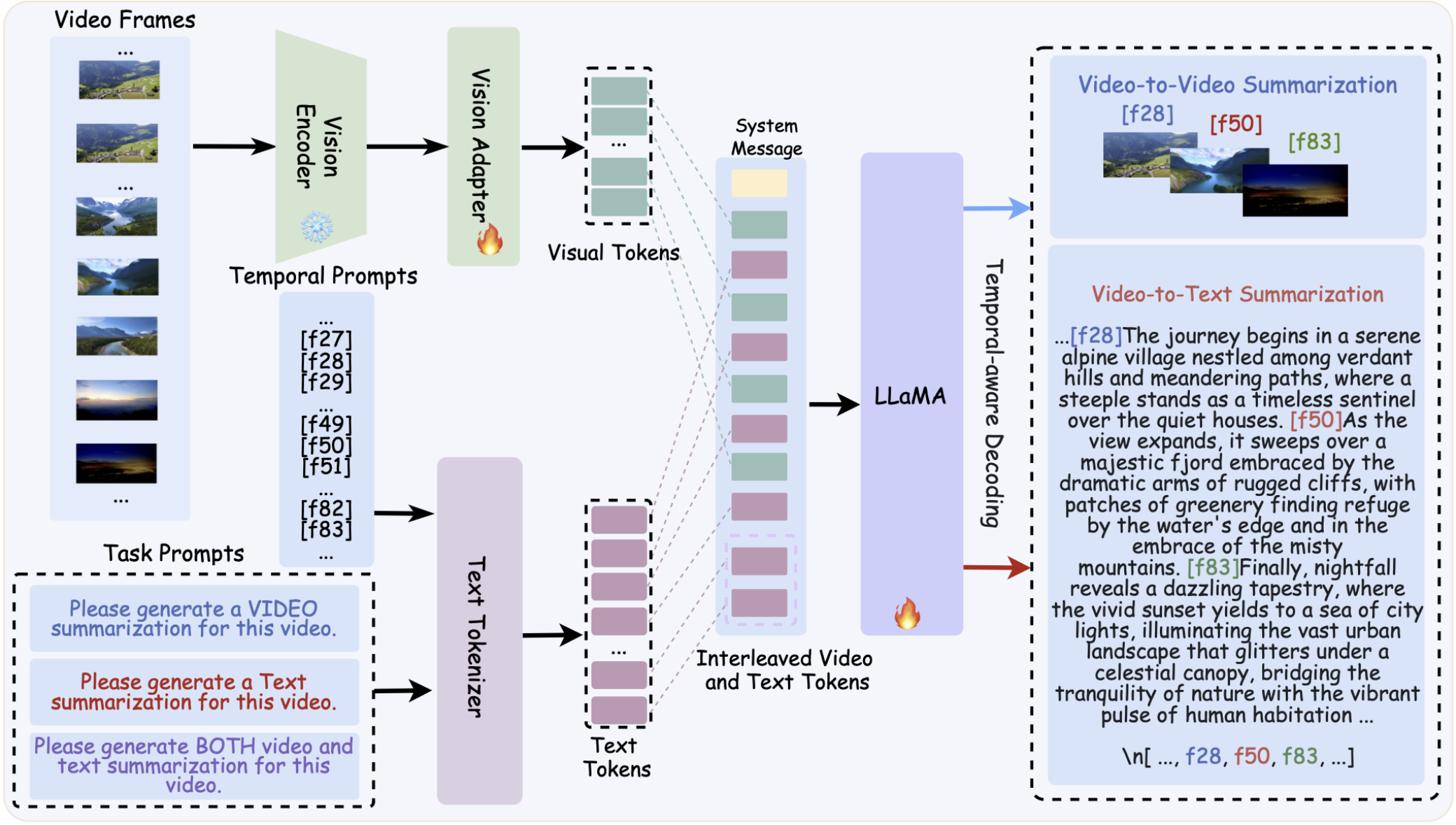 Hang Hua*, Yunlong Tang*, Chenliang Xu, and Jiebo Luo†In Proceedings of the AAAI Conference on Artificial Intelligence (AAAI), 2025
Hang Hua*, Yunlong Tang*, Chenliang Xu, and Jiebo Luo†In Proceedings of the AAAI Conference on Artificial Intelligence (AAAI), 2025@inproceedings{hua2024v2xum, title = {V2Xum-LLM: Cross-modal Video Summarization with Temporal Prompt Instruction Tuning}, author = {Hua, Hang and Tang, Yunlong and Xu, Chenliang and Luo, Jiebo}, booktitle = {Proceedings of the AAAI Conference on Artificial Intelligence (AAAI)}, volume = {39}, number = {4}, pages = {3599-3607}, year = {2025}, doi = {10.1609/aaai.v39i4.32374}, } - AAAI
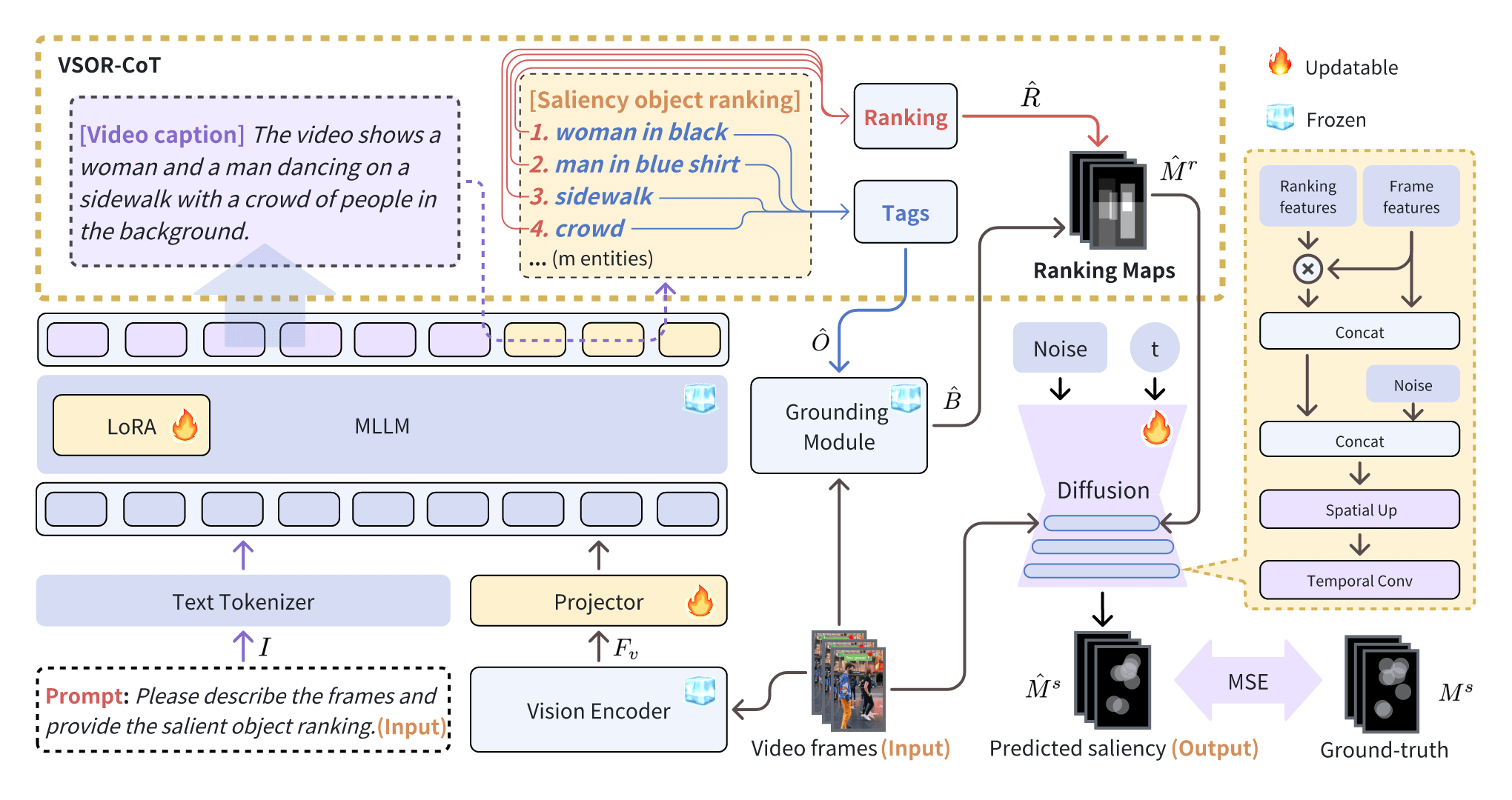 Yunlong Tang, Gen Zhan, Li Yang, Yiting Liao, and Chenliang Xu†In Proceedings of the AAAI Conference on Artificial Intelligence (AAAI), 2025
Yunlong Tang, Gen Zhan, Li Yang, Yiting Liao, and Chenliang Xu†In Proceedings of the AAAI Conference on Artificial Intelligence (AAAI), 2025Video saliency prediction aims to identify the regions in a video that attract human attention and gaze, driven by bottom-up features from the video and top-down processes like memory and cognition. Among these top-down influences, language plays a crucial role in guiding attention by shaping how visual information is interpreted. Existing methods primarily focus on modeling perceptual information while neglecting the reasoning process facilitated by language, where ranking cues are crucial outcomes of this process and practical guidance for saliency prediction. In this paper, we propose CaRDiff (Caption, Rank, and generate with Diffusion), a framework that imitates the process by integrating multimodal large language model (MLLM), a grounding module, and a diffusion model, to enhance video saliency prediction. Specifically, we introduce a novel prompting method VSOR-CoT (Video Salient Object Ranking Chain of Thought), which utilizes an MLLM with a grounding module to caption video content and infer salient objects along with their rankings and positions. This process derives ranking maps that can be sufficiently leveraged by the diffusion model to decode the saliency maps for the given video accurately. Extensive experiments show the effectiveness of VSOR-CoT in improving the performance of video saliency prediction. The proposed CaRDiff performs better than state-of-the-art models on the MVS dataset and demonstrates cross-dataset capabilities on the DHF1k dataset through zero-shot evaluation.
@inproceedings{tang2024cardiff, title = {CaRDiff: Video Salient Object Ranking Chain of Thought Reasoning for Saliency Prediction with Diffusion}, author = {Tang, Yunlong and Zhan, Gen and Yang, Li and Liao, Yiting and Xu, Chenliang}, booktitle = {Proceedings of the AAAI Conference on Artificial Intelligence (AAAI)}, year = {2025}, doi = {10.1609/aaai.v39i7.32785}, volume = {39}, number = {7}, pages = {7302-7310}, }















- NeurIPS Yunlong Tang, Pinxin Liu, Zhangyun Tan, Mingqian Feng, Rui Mao, Chao Huang, Jing Bi, Yunzhong Xiao, Susan Liang, Hang Hua, and 4 more authorsThe Thirty-ninth Annual Conference on Neural Information Processing Systems (NeurIPS) Datasets and Benchmarks Track, 2025
@article{tang2025mmperspective, title = {MMPerspective: Do MLLMs Understand Perspective? A Comprehensive Benchmark for Perspective Perception, Reasoning, and Robustness}, author = {Tang, Yunlong and Liu, Pinxin and Tan, Zhangyun and Feng, Mingqian and Mao, Rui and Huang, Chao and Bi, Jing and Xiao, Yunzhong and Liang, Susan and Hua, Hang and Vosoughi, Ali and Song, Luchuan and Zhang, Zeliang and Xu, Chenliang}, journal = {The Thirty-ninth Annual Conference on Neural Information Processing Systems (NeurIPS) Datasets and Benchmarks Track}, year = {2025}, } - ICCV Workshop
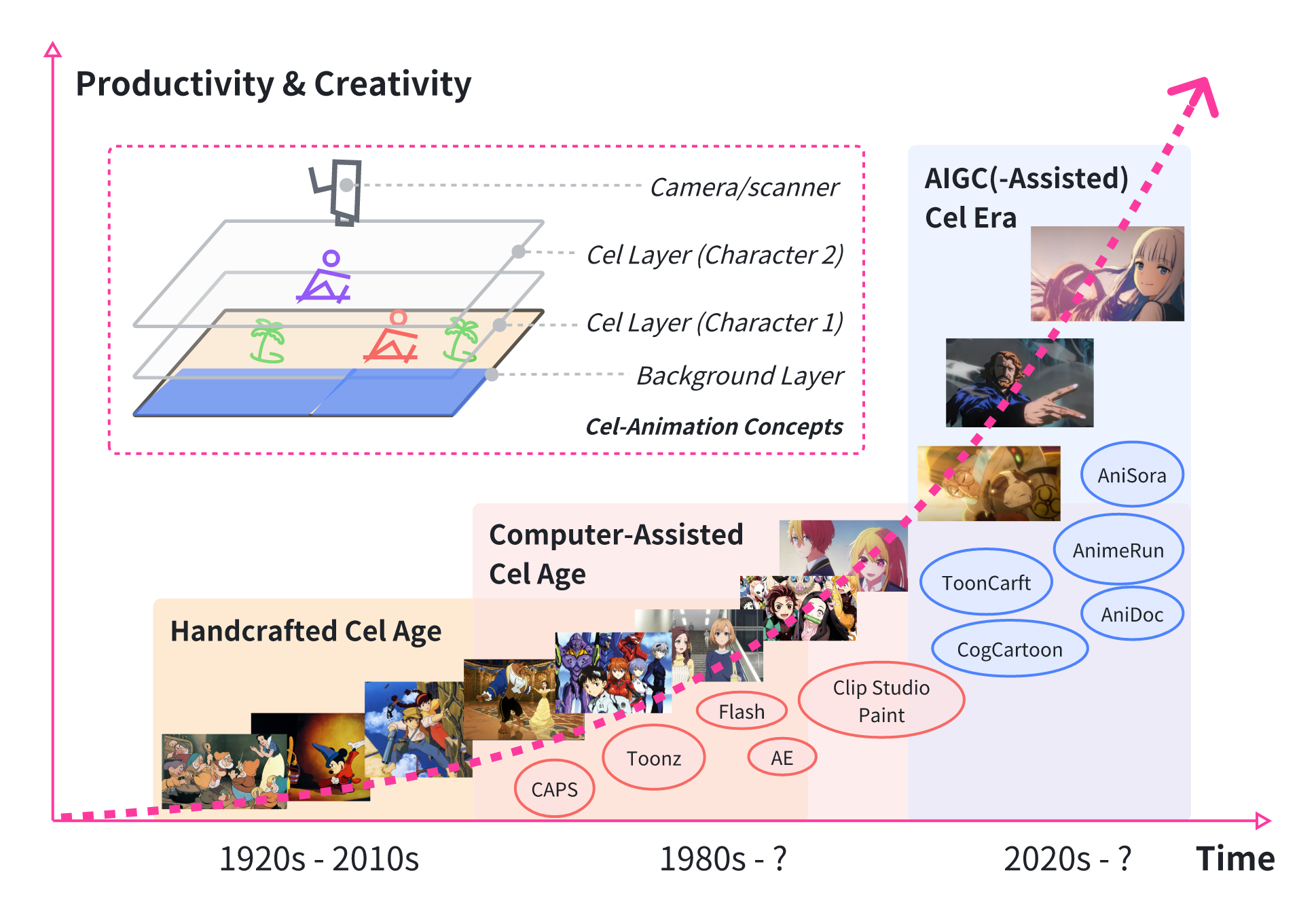 Yunlong Tang, Junjia Guo, Pinxin Liu, Zhiyuan Wang, Hang Hua, Jia-Xing Zhong, Yunzhong Xiao, Chao Huang, Luchuan Song, Susan Liang, and 7 more authorsProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) Workshops, 2025
Yunlong Tang, Junjia Guo, Pinxin Liu, Zhiyuan Wang, Hang Hua, Jia-Xing Zhong, Yunzhong Xiao, Chao Huang, Luchuan Song, Susan Liang, and 7 more authorsProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) Workshops, 2025@article{tang2025ai4anime, title = {Generative AI for Cel-Animation: A Survey 🔥🔥🔥}, author = {Tang, Yunlong and Guo, Junjia and Liu, Pinxin and Wang, Zhiyuan and Hua, Hang and Zhong, Jia-Xing and Xiao, Yunzhong and Huang, Chao and Song, Luchuan and Liang, Susan and Song, Yizhi and He, Liu and Bi, Jing and Feng, Mingqian and Li, Xinyang and Zhang, Zeliang and Xu, Chenliang}, journal = {Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) Workshops}, year = {2025}, pages = {3778-3791}, } - ICMC
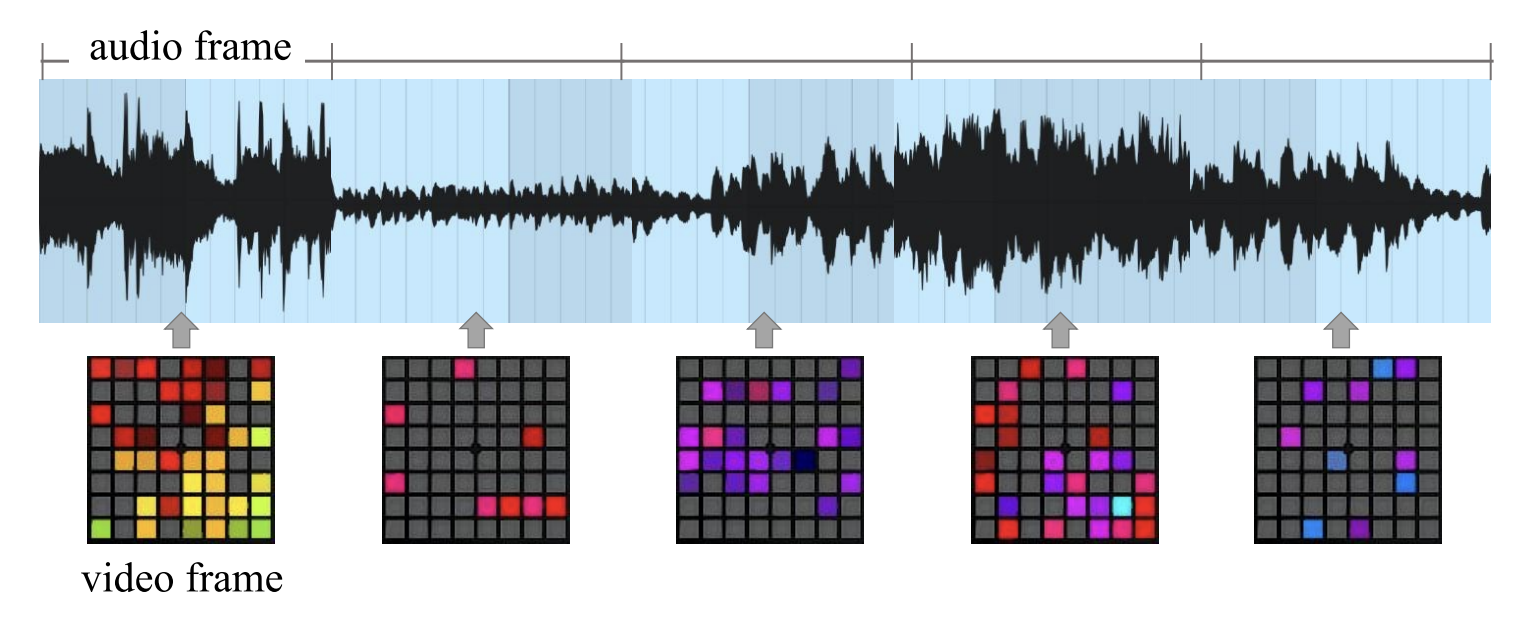 Siting Xu*, Yunlong Tang*, and Feng Zheng†In Proceedings of the International Computer Music Conference (ICMC), 2023
Siting Xu*, Yunlong Tang*, and Feng Zheng†In Proceedings of the International Computer Music Conference (ICMC), 2023Launchpad is a popular music instrument for live performance and music production. In this paper, we propose LaunchpadGPT, a language model that can generate music visualization designs for Launchpad. We train the model on a large-scale dataset of music visualization designs and demonstrate its effectiveness in generating diverse and creative designs. We also develop a web-based platform that allows users to interact with the model and generate music visualization designs in real-time. Our code is available at https://github.com/yunlong10/LaunchpadGPT.
@inproceedings{xu2023launchpadgpt, title = {LaunchpadGPT: Language Model as Music Visualization Designer on Launchpad}, author = {Xu, Siting and Tang, Yunlong and Zheng, Feng}, booktitle = {Proceedings of the International Computer Music Conference (ICMC)}, year = {2023}, pages = {213-217}, }




Misc.
Fun Facts
- 🩵 Preferred names: Yolo (en) or 芸珑 (zh).
- 🍭 I’m into ACG, J-pop, singing, and cosplay.
- 😝 Maybe I’m just cosplaying as a researcher—who knows?