Publications
* Equal Contribution | † Corresponding Author
2026
- AAAI Demo
 Yunlong Tang, Jing Bi, Chao Huang, Susan Liang, Daiki Shimada, Hang Hua, Yunzhong Xiao, Yizhi Song, Pinxin Liu, Mingqian Feng, and 9 more authorsAAAI Demonstartion Program; arXiv preprint arXiv:2504.05541, 2026
Yunlong Tang, Jing Bi, Chao Huang, Susan Liang, Daiki Shimada, Hang Hua, Yunzhong Xiao, Yizhi Song, Pinxin Liu, Mingqian Feng, and 9 more authorsAAAI Demonstartion Program; arXiv preprint arXiv:2504.05541, 2026We present CAT-V (Caption AnyThing in Video), a training-free framework for fine-grained object-centric video captioning that enables detailed descriptions of user-selected objects through time. CAT-V integrates three key components: a Segmenter based on SAMURAI for precise object segmentation across frames, a Temporal Analyzer powered by TRACE-Uni for accurate event boundary detection and temporal analysis, and a Captioner using InternVL-2.5 for generating detailed object-centric descriptions. Through spatiotemporal visual prompts and chain-of-thought reasoning, our framework generates detailed, temporally-aware descriptions of objects’ attributes, actions, statuses, interactions, and environmental contexts without requiring additional training data. CAT-V supports flexible user interactions through various visual prompts (points, bounding boxes, and irregular regions) and maintains temporal sensitivity by tracking object states and interactions across different time segments. Our approach addresses limitations of existing video captioning methods, which either produce overly abstract descriptions or lack object-level precision, enabling fine-grained, object-specific descriptions while maintaining temporal coherence and spatial accuracy. The GitHub repository for this project is available at: https://github.com/yunlong10/CAT-V
@article{tang2025catv, title = {Caption Anything in Video: Fine-grained Object-centric Captioning via Spatiotemporal Multimodal Prompting}, author = {Tang, Yunlong and Bi, Jing and Huang, Chao and Liang, Susan and Shimada, Daiki and Hua, Hang and Xiao, Yunzhong and Song, Yizhi and Liu, Pinxin and Feng, Mingqian and Guo, Junjia and Liu, Zhuo and Song, Luchuan and Vosoughi, Ali and He, Jinxi and He, Liu and Zhang, Zeliang and Luo, Jiebo and Xu, Chenliang}, journal = {AAAI Demonstartion Program; arXiv preprint arXiv:2504.05541}, year = {2026}, }


2025
-
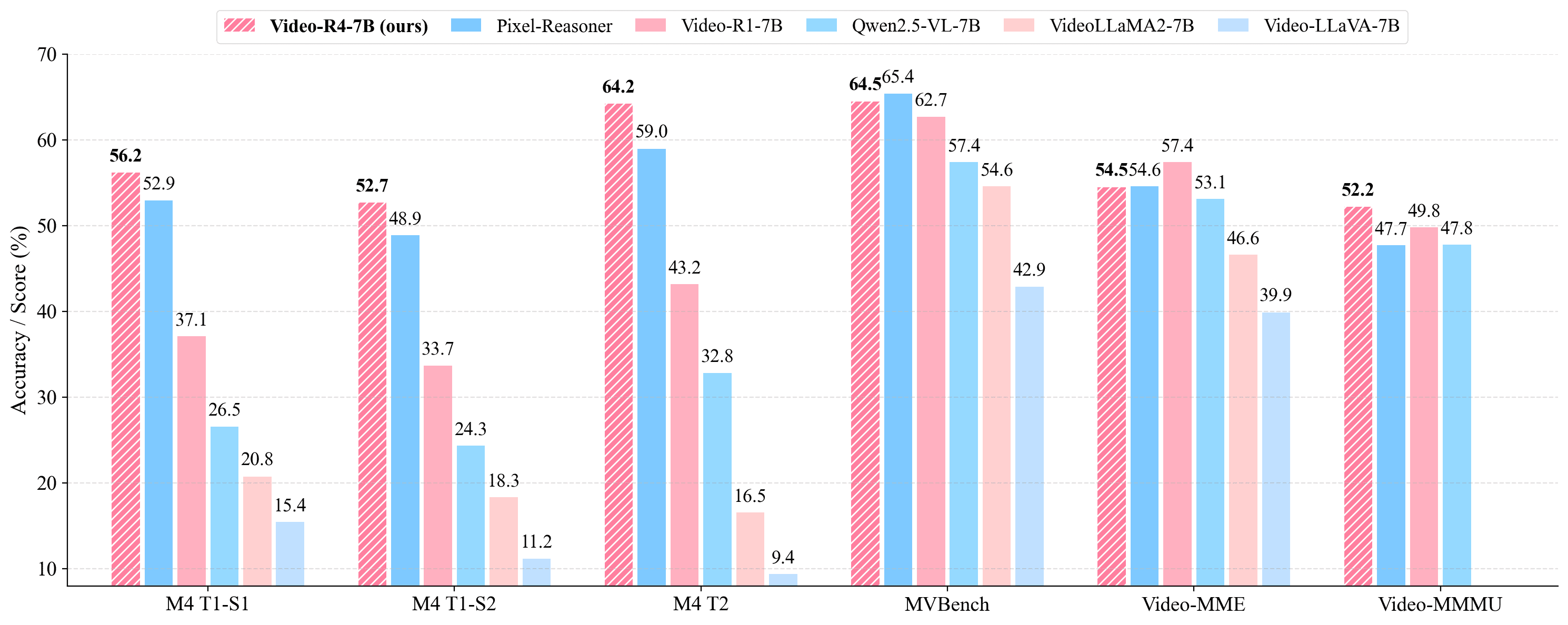 Yolo Yunlong Tang, Daiki Shimada, Hang Hua, Chao Huang, Jing Bi, Rogerio Feris, and Chenliang XuarXiv preprint arXiv:2511.17490, 2025
Yolo Yunlong Tang, Daiki Shimada, Hang Hua, Chao Huang, Jing Bi, Rogerio Feris, and Chenliang XuarXiv preprint arXiv:2511.17490, 2025Understanding text-rich videos requires reading small, transient textual cues that often demand repeated inspection. Yet most video QA models rely on single-pass perception over fixed frames, leading to hallucinations and failures on fine-grained evidence. Inspired by how humans pause, zoom, and re-read critical regions, we introduce Video-R4 (Reinforcing Text-Rich Video Reasoning with Visual Rumination), a video reasoning LMM that performs visual rumination: iteratively selecting frames, zooming into informative regions, re-encoding retrieved pixels, and updating its reasoning state. We construct two datasets with executable rumination trajectories: Video-R4-CoT-17k for supervised practice and Video-R4-RL-30k for reinforcement learning. We propose a multi-stage rumination learning framework that progressively finetunes a 7B LMM to learn atomic and mixing visual operations via SFT and GRPO-based RL. Video-R4-7B achieves state-of-the-art results on M4-ViteVQA and further generalizes to multi-page document QA, slides QA, and generic video QA, demonstrating that iterative rumination is an effective paradigm for pixel-grounded multimodal reasoning. For more information, readers are recommended to visit the repository at https://github.com/yunlong10/Video-R4.
@article{tang2025videor4, title = {Video-R4: Reinforcing Text-Rich Video Reasoning with Visual Rumination}, author = {Tang, Yolo Yunlong and Shimada, Daiki and Hua, Hang and Huang, Chao and Bi, Jing and Feris, Rogerio and Xu, Chenliang}, journal = {arXiv preprint arXiv:2511.17490}, year = {2025}, } -
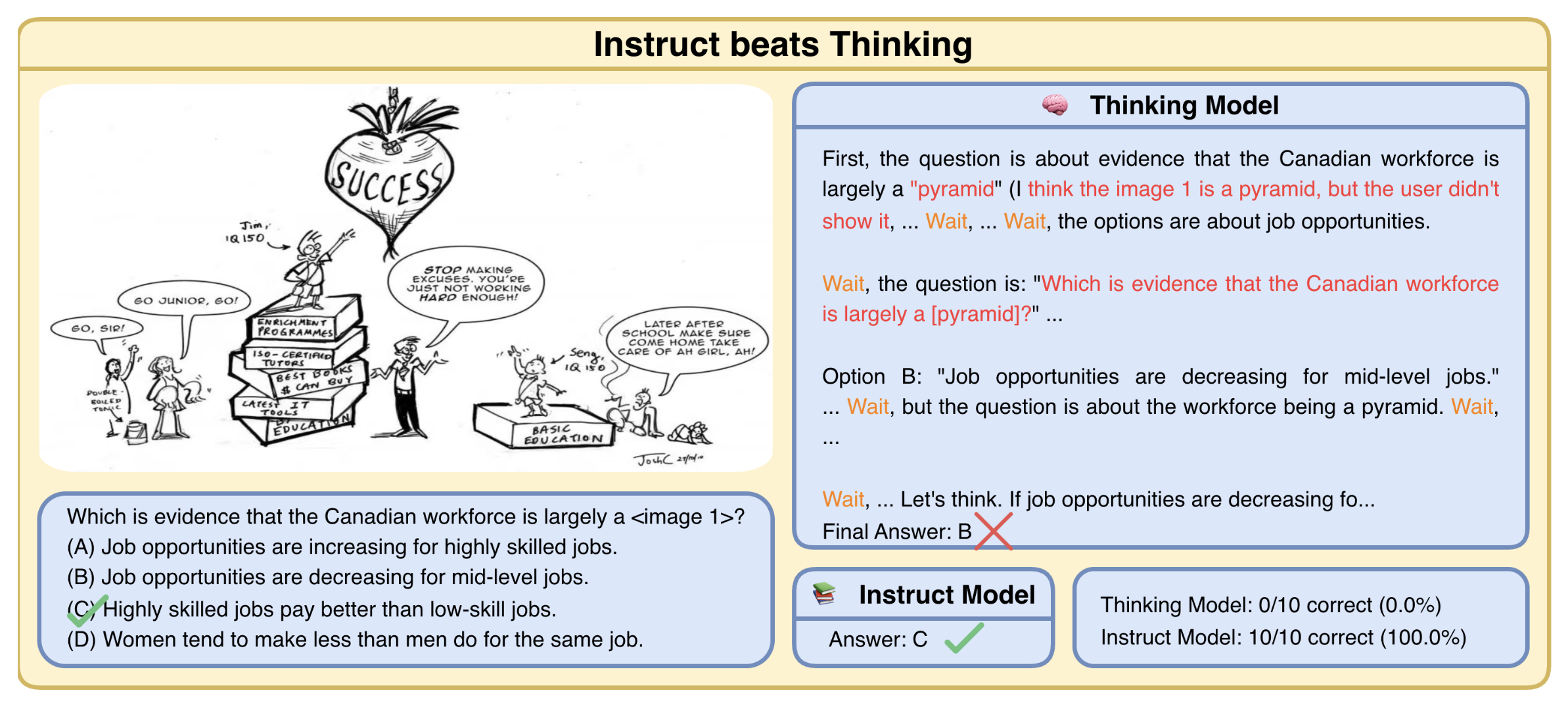 Jing Bi, Filippos Bellos, Junjia Guo, Yayuan Li, Chao Huang, Yolo Y. Tang, Luchuan Song, Susan Liang, Zhongfei Mark Zhang, Jason J Corso, and 1 more authorarXiv preprint arXiv:2511.15613, 2025
Jing Bi, Filippos Bellos, Junjia Guo, Yayuan Li, Chao Huang, Yolo Y. Tang, Luchuan Song, Susan Liang, Zhongfei Mark Zhang, Jason J Corso, and 1 more authorarXiv preprint arXiv:2511.15613, 2025Test-time thinking (that is, generating explicit intermediate reasoning chains) is known to boost performance in large language models and has recently shown strong gains for large vision language models (LVLMs). However, despite these promising results, there is still no systematic analysis of how thinking actually affects visual reasoning. We provide the first such analysis with a large scale, controlled comparison of thinking for LVLMs, evaluating ten variants from the InternVL3.5 and Qwen3-VL families on MMMU-val under generous token budgets and multi pass decoding. We show that more thinking is not always better; long chains often yield long wrong trajectories that ignore the image and underperform the same models run in standard instruct mode. A deeper analysis reveals that certain short lookback phrases, which explicitly refer back to the image, are strongly enriched in successful trajectories and correlate with better visual grounding. Building on this insight, we propose uncertainty guided lookback, a training free decoding strategy that combines an uncertainty signal with adaptive lookback prompts and breadth search. Our method improves overall MMMU performance, delivers the largest gains in categories where standard thinking is weak, and outperforms several strong decoding baselines, setting a new state of the art under fixed model families and token budgets. We further show that this decoding strategy generalizes, yielding consistent improvements on five additional benchmarks, including two broad multimodal suites and math focused visual reasoning datasets.
@article{bi2025think, title = {When to Think and When to Look: Uncertainty-Guided Lookback}, author = {Bi, Jing and Bellos, Filippos and Guo, Junjia and Li, Yayuan and Huang, Chao and Tang, Yolo Y. and Song, Luchuan and Liang, Susan and Zhang, Zhongfei Mark and Corso, Jason J and Xu, Chenliang}, journal = {arXiv preprint arXiv:2511.15613}, year = {2025}, } -
 Yunzhong Xiao, Yangmin Li, Hewei Wang, Yolo Yunlong Tang, and Zora Zhiruo WangarXiv preprint arXiv:2510.06664, 2025
Yunzhong Xiao, Yangmin Li, Hewei Wang, Yolo Yunlong Tang, and Zora Zhiruo WangarXiv preprint arXiv:2510.06664, 2025Agents utilizing tools powered by large language models (LLMs) or vision-language models (VLMs) have demonstrated remarkable progress in diverse tasks across text and visual modalities. Unlike traditional tools such as calculators, which give deterministic outputs, neural tools perform uncertainly across task scenarios. While different tools for a task may excel in varied scenarios, existing agents typically rely on fixed tools, thus limiting the flexibility in selecting the most suitable tool for specific tasks. In contrast, humans snowball their understanding of the capabilities of different tools by interacting with them, and apply this knowledge to select the optimal tool when solving a future task. To build agents that similarly benefit from this process, we propose ToolMem that enables agents to develop memories of tool capabilities from previous interactions, by summarizing their strengths and weaknesses and storing them in memory; at inference, the agent can retrieve relevant entries from ToolMem, and select the best tool to solve individual tasks more accurately. We evaluate ToolMem on learning varied text generation and text-to-image generation neural tools. Compared to no-memory, generic agents, we find ToolMem-augmented agents predict tool performance 14.8% and 28.7% more accurately across text and multimodal generation scenarios. Moreover, ToolMem facilitates optimal tool selection among multiple choices by 21% and 24% absolute increases in respective scenarios.
@article{xiao2025toolmem, title = {ToolMem: Enhancing Multimodal Agents with Learnable Tool Capability Memory}, author = {Xiao, Yunzhong and Li, Yangmin and Wang, Hewei and Tang, Yolo Yunlong and Wang, Zora Zhiruo}, journal = {arXiv preprint arXiv:2510.06664}, year = {2025}, } -
 Yolo Yunlong Tang, Jing Bi, Pinxin Liu, Zhenyu Pan, Zhangyun Tan, Qianxiang Shen, Jiani Liu, Hang Hua, Junjia Guo, Yunzhong Xiao, and 17 more authorsarXiv preprint arXiv:2510.05034, 2025
Yolo Yunlong Tang, Jing Bi, Pinxin Liu, Zhenyu Pan, Zhangyun Tan, Qianxiang Shen, Jiani Liu, Hang Hua, Junjia Guo, Yunzhong Xiao, and 17 more authorsarXiv preprint arXiv:2510.05034, 2025Video understanding represents the most challenging frontier in computer vision. It requires models to reason about complex spatiotemporal relationships, long-term dependencies, and multimodal evidence. The recent emergence of Video-Large Multimodal Models (Video-LMMs), which integrate visual encoders with powerful decoder-based language models, has demonstrated remarkable capabilities in video understanding tasks. However, the critical phase that transforms these models from basic perception systems into sophisticated reasoning engines, post-training, remains fragmented across the literature. This survey provides the first comprehensive examination of post-training methodologies for Video-LMMs, encompassing three fundamental pillars: supervised fine-tuning (SFT) with chain-of-thought, reinforcement learning (RL) from verifiable objectives, and test-time scaling (TTS) through enhanced inference computation. We present a structured taxonomy that clarifies the roles, interconnections, and video-specific adaptations of these techniques, addressing unique challenges such as temporal localization, spatiotemporal grounding, long video efficiency, and multimodal evidence integration. Through systematic analysis of representative methods, we synthesize key design principles, insights, and evaluation protocols while identifying critical open challenges in reward design, scalability, and cost-performance optimization. We further curate essential benchmarks, datasets, and metrics to facilitate rigorous assessment of post-training effectiveness. This survey aims to provide researchers and practitioners with a unified framework for advancing Video-LMM capabilities. Additional resources and updates are maintained at: https://arxiv.org/abs/2510.05034
@article{tang2025videolmm_posttraining, title = {Video-LMM Post-Training: A Deep Dive into Video Reasoning with Large Multimodal Models 🔥🔥🔥}, author = {Tang, Yolo Yunlong and Bi, Jing and Liu, Pinxin and Pan, Zhenyu and Tan, Zhangyun and Shen, Qianxiang and Liu, Jiani and Hua, Hang and Guo, Junjia and Xiao, Yunzhong and Huang, Chao and Wang, Zhiyuan and Liang, Susan and Liu, Xinyi and Song, Yizhi and Huang, Junhua and Zhong, Jia-Xing and Li, Bozheng and Qi, Daiqing and Zeng, Ziyun and Vosoughi, Ali and Song, Luchuan and Zhang, Zeliang and Shimada, Daiki and Liu, Han and Luo, Jiebo and Xu, Chenliang}, journal = {arXiv preprint arXiv:2510.05034}, year = {2025}, } -
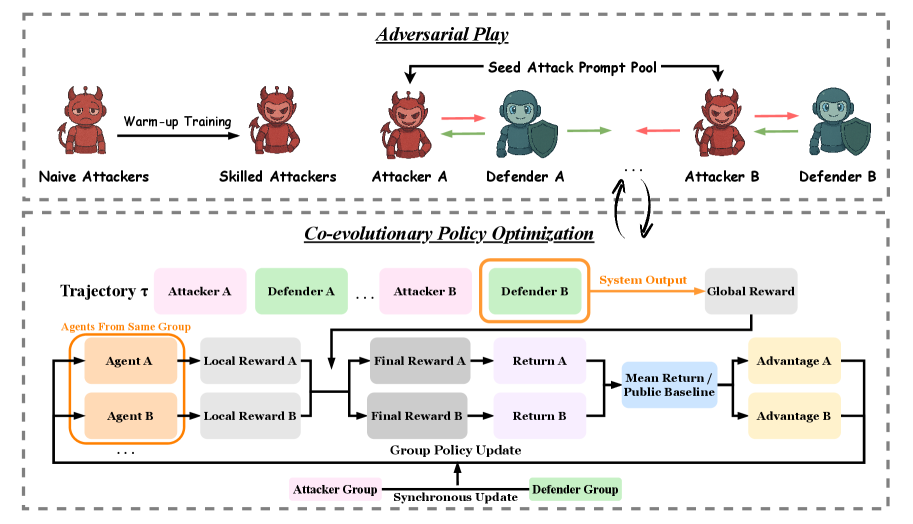 Zhenyu Pan, Yiting Zhang, Zhuo Liu, Yolo Yunlong Tang, Zeliang Zhang, Haozheng Luo, Yuwei Han, Jianshu Zhang, Dennis Wu, Hong-Yu Chen, and 6 more authorsarXiv preprint arXiv:2510.01586, 2025
Zhenyu Pan, Yiting Zhang, Zhuo Liu, Yolo Yunlong Tang, Zeliang Zhang, Haozheng Luo, Yuwei Han, Jianshu Zhang, Dennis Wu, Hong-Yu Chen, and 6 more authorsarXiv preprint arXiv:2510.01586, 2025LLM-based multi-agent systems excel at planning, tool use, and role coordination, but their openness and interaction complexity also expose them to jailbreak, prompt-injection, and adversarial collaboration. Existing defenses fall into two lines: (i) self-verification that asks each agent to pre-filter unsafe instructions before execution, and (ii) external guard modules that police behaviors. The former often underperforms because a standalone agent lacks sufficient capacity to detect cross-agent unsafe chains and delegation-induced risks; the latter increases system overhead and creates a single-point-of-failure—once compromised, system-wide safety collapses, and adding more guards worsens cost and complexity. To solve these challenges, we propose AdvEvo-MARL, a co-evolutionary multi-agent reinforcement learning framework that internalizes safety into task agents. Rather than relying on external guards, AdvEvo-MARL jointly optimizes attackers (which synthesize evolving jailbreak prompts) and defenders (task agents trained to both accomplish their duties and resist attacks) in adversarial learning environments. To stabilize learning and foster cooperation, we introduce a public baseline for advantage estimation: agents within the same functional group share a group-level mean-return baseline, enabling lower-variance updates and stronger intra-group coordination. Across representative attack scenarios, AdvEvo-MARL consistently keeps attack-success rate (ASR) below 20%, whereas baselines reach up to 38.33%, while preserving—and sometimes improving—task accuracy (up to +3.67% on reasoning tasks). These results show that safety and utility can be jointly improved without relying on extra guard agents or added system overhead.
@article{pan2025advevo_marl, title = {AdvEvo-MARL: Shaping Internalized Safety through Adversarial Co-Evolution in Multi-Agent Reinforcement Learning}, author = {Pan, Zhenyu and Zhang, Yiting and Liu, Zhuo and Tang, Yolo Yunlong and Zhang, Zeliang and Luo, Haozheng and Han, Yuwei and Zhang, Jianshu and Wu, Dennis and Chen, Hong-Yu and Lu, Haoran and Fang, Haoyang and Li, Manling and Xu, Chenliang and Yu, Philip S. and Liu, Han}, journal = {arXiv preprint arXiv:2510.01586}, year = {2025}, } - NeurIPS
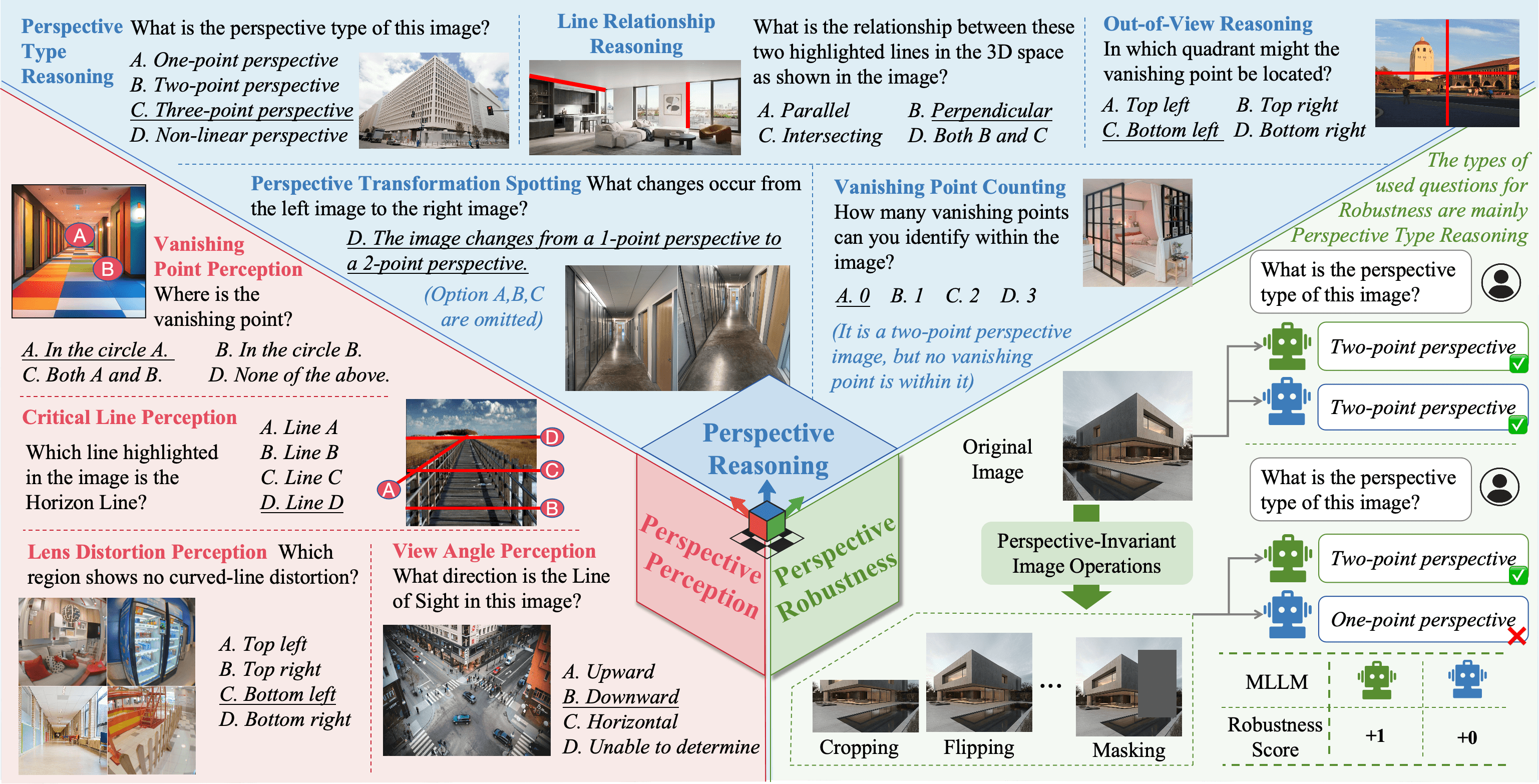 Yunlong Tang, Pinxin Liu, Zhangyun Tan, Mingqian Feng, Rui Mao, Chao Huang, Jing Bi, Yunzhong Xiao, Susan Liang, Hang Hua, and 4 more authorsThe Thirty-ninth Annual Conference on Neural Information Processing Systems (NeurIPS) Datasets and Benchmarks Track, 2025
Yunlong Tang, Pinxin Liu, Zhangyun Tan, Mingqian Feng, Rui Mao, Chao Huang, Jing Bi, Yunzhong Xiao, Susan Liang, Hang Hua, and 4 more authorsThe Thirty-ninth Annual Conference on Neural Information Processing Systems (NeurIPS) Datasets and Benchmarks Track, 2025@article{tang2025mmperspective, title = {MMPerspective: Do MLLMs Understand Perspective? A Comprehensive Benchmark for Perspective Perception, Reasoning, and Robustness}, author = {Tang, Yunlong and Liu, Pinxin and Tan, Zhangyun and Feng, Mingqian and Mao, Rui and Huang, Chao and Bi, Jing and Xiao, Yunzhong and Liang, Susan and Hua, Hang and Vosoughi, Ali and Song, Luchuan and Zhang, Zeliang and Xu, Chenliang}, journal = {The Thirty-ninth Annual Conference on Neural Information Processing Systems (NeurIPS) Datasets and Benchmarks Track}, year = {2025}, } - NeurIPS
 Hang Hua, Ziyun Zeng, Yizhi Song, Yunlong Tang, Liu He, Daniel Aliaga, Wei Xiong, and Jiebo LuoThe Thirty-ninth Annual Conference on Neural Information Processing Systems (NeurIPS) Datasets and Benchmarks Track, 2025
Hang Hua, Ziyun Zeng, Yizhi Song, Yunlong Tang, Liu He, Daniel Aliaga, Wei Xiong, and Jiebo LuoThe Thirty-ninth Annual Conference on Neural Information Processing Systems (NeurIPS) Datasets and Benchmarks Track, 2025@article{hua2025mmigbench, title = {MMIG-Bench: Towards Comprehensive and Explainable Evaluation of Multi-Modal Image Generation Models}, author = {Hua, Hang and Zeng, Ziyun and Song, Yizhi and Tang, Yunlong and He, Liu and Aliaga, Daniel and Xiong, Wei and Luo, Jiebo}, journal = {The Thirty-ninth Annual Conference on Neural Information Processing Systems (NeurIPS) Datasets and Benchmarks Track}, year = {2025}, } - NeurIPS
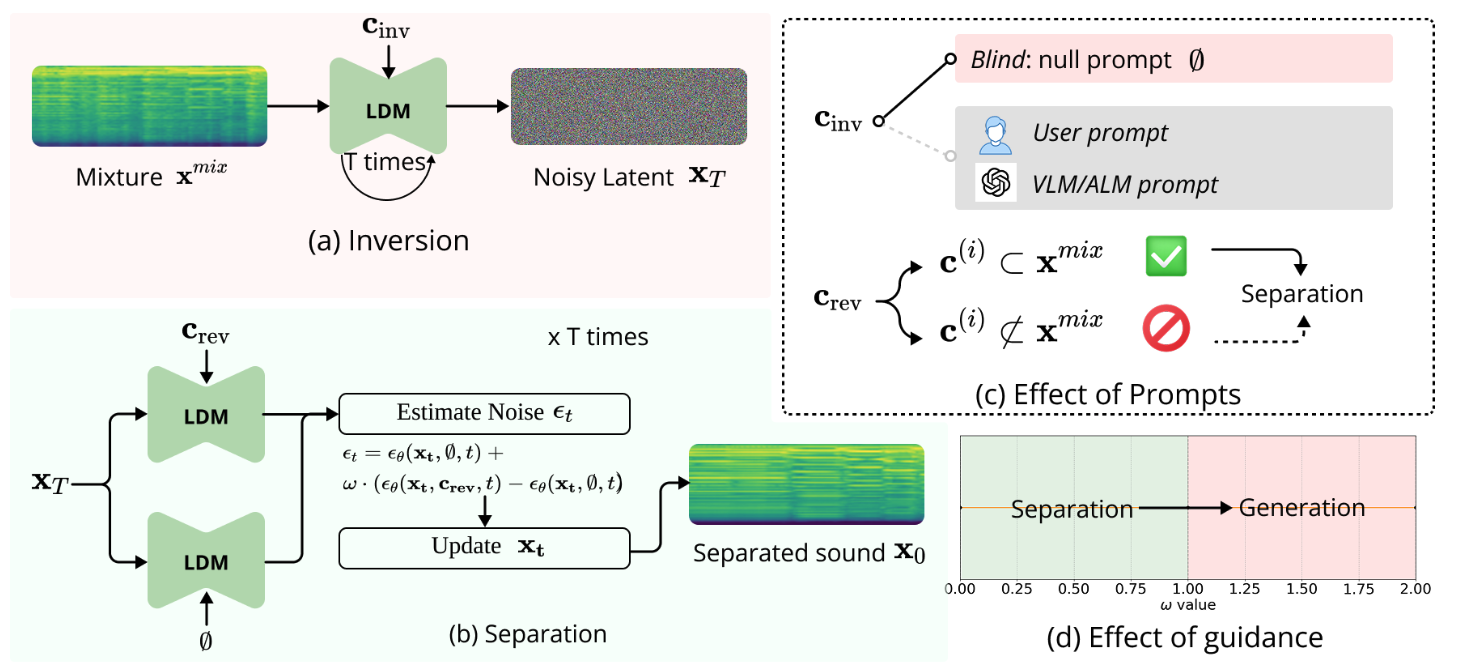 Chao Huang, Yuesheng Ma, Junxuan Huang, Susan Liang, Yunlong Tang, Jing Bi, Wenqiang Liu, Nima Mesgarani, and Chenliang XuThe Thirty-ninth Annual Conference on Neural Information Processing Systems (NeurIPS), 2025
Chao Huang, Yuesheng Ma, Junxuan Huang, Susan Liang, Yunlong Tang, Jing Bi, Wenqiang Liu, Nima Mesgarani, and Chenliang XuThe Thirty-ninth Annual Conference on Neural Information Processing Systems (NeurIPS), 2025Audio source separation is fundamental for machines to understand complex acoustic environments and underpins numerous audio applications. Current supervised deep learning approaches, while powerful, are limited by the need for extensive, task-specific labeled data and struggle to generalize to the immense variability and open-set nature of real-world acoustic scenes. Inspired by the success of generative foundation models, we investigate whether pre-trained text-guided audio diffusion models can overcome these limitations. We make a surprising discovery: zero-shot source separation can be achieved purely through a pre-trained text-guided audio diffusion model under the right configuration. Our method, named ZeroSep, works by inverting the mixed audio into the diffusion model’s latent space and then using text conditioning to guide the denoising process to recover individual sources. Without any task-specific training or fine-tuning, ZeroSep repurposes the generative diffusion model for a discriminative separation task and inherently supports open-set scenarios through its rich textual priors. ZeroSep is compatible with a variety of pre-trained text-guided audio diffusion backbones and delivers strong separation performance on multiple separation benchmarks, surpassing even supervised methods.
@article{huang2025zerosep, title = {ZeroSep: Separate Anything in Audio with Zero Training}, author = {Huang, Chao and Ma, Yuesheng and Huang, Junxuan and Liang, Susan and Tang, Yunlong and Bi, Jing and Liu, Wenqiang and Mesgarani, Nima and Xu, Chenliang}, journal = {The Thirty-ninth Annual Conference on Neural Information Processing Systems (NeurIPS)}, year = {2025}, } - NeurIPS
 Jiani Liu, Zhiyuan Wang, Zeliang Zhang, Chao Huang, Susan Liang, Yunlong Tang, and Chenliang XuThe Thirty-ninth Annual Conference on Neural Information Processing Systems (NeurIPS), 2025
Jiani Liu, Zhiyuan Wang, Zeliang Zhang, Chao Huang, Susan Liang, Yunlong Tang, and Chenliang XuThe Thirty-ninth Annual Conference on Neural Information Processing Systems (NeurIPS), 2025Vision Transformers (ViTs) have demonstrated remarkable success in computer vision tasks, yet their vulnerability to adversarial attacks remains a critical concern. While existing methods focus on improving adversarial robustness through training strategies, we explore a novel perspective: leveraging the inherent computation redundancy in ViTs to enhance adversarial transferability. We observe that ViTs contain significant computational redundancy across different layers and attention heads, which can be strategically exploited to generate more transferable adversarial examples. Our approach, named Harnessing Redundancy for Transferability (HRT), identifies and utilizes the most influential computation paths in ViTs to craft adversarial examples that are more likely to transfer across different models and architectures. Through extensive experiments on ImageNet and CIFAR-10, we demonstrate that HRT significantly improves adversarial transferability compared to existing methods, achieving up to 15% higher success rates in black-box attacks. Our findings provide new insights into the relationship between model architecture and adversarial robustness, opening new directions for both attack and defense strategies.
@article{liu2025harnessing, title = {Harnessing the Computation Redundancy in ViTs to Boost Adversarial Transferability}, author = {Liu, Jiani and Wang, Zhiyuan and Zhang, Zeliang and Huang, Chao and Liang, Susan and Tang, Yunlong and Xu, Chenliang}, journal = {The Thirty-ninth Annual Conference on Neural Information Processing Systems (NeurIPS)}, year = {2025}, } - ICCV
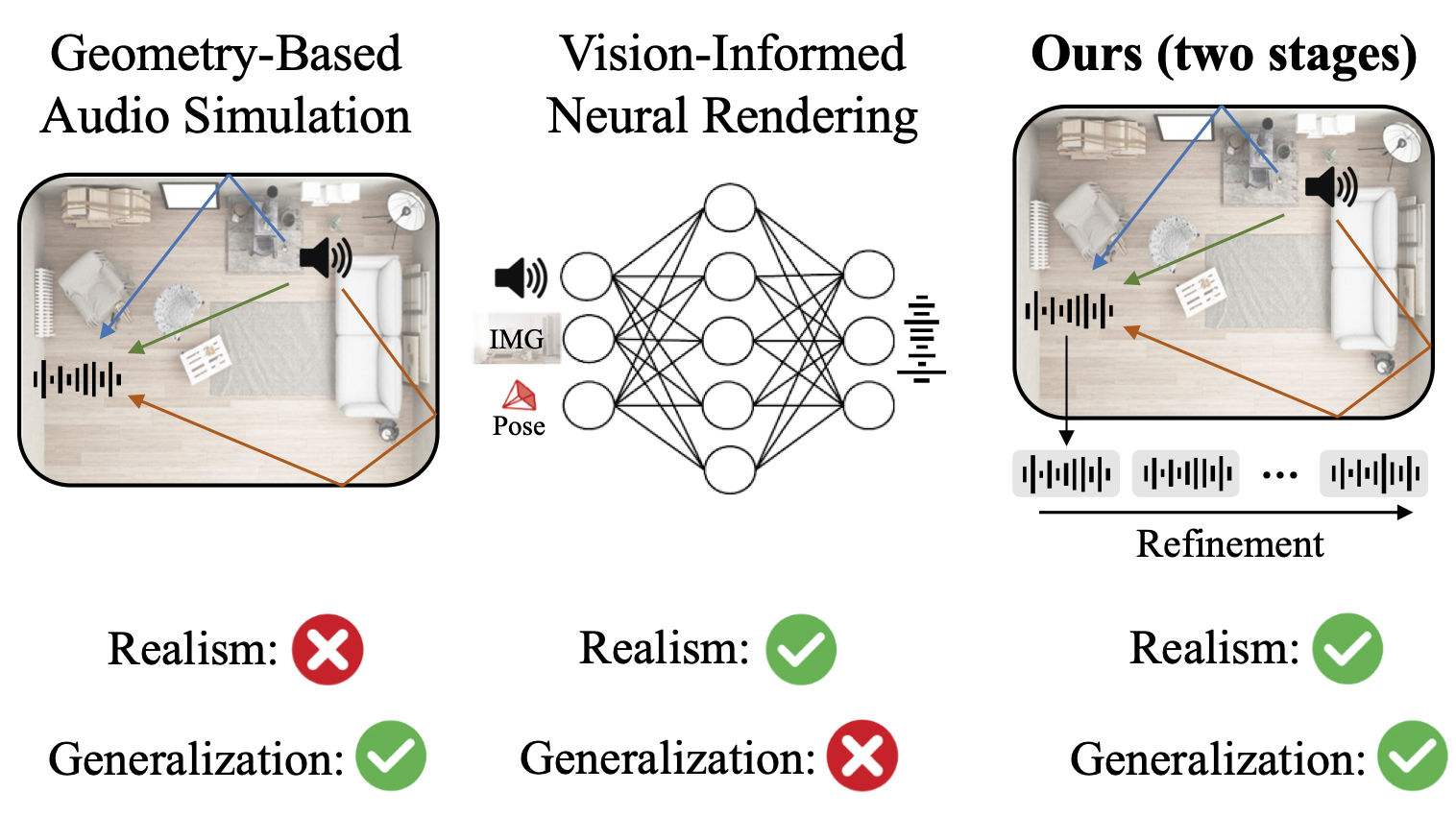 Susan Liang, Chao Huang, Yunlong Tang, Zeliang Zhang, and Chenliang XuIn Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2025
Susan Liang, Chao Huang, Yunlong Tang, Zeliang Zhang, and Chenliang XuIn Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2025The Audio-Visual Acoustic Synthesis (AVAS) task aims to model realistic audio propagation behavior within a specific visual scene. Prior works often rely on sparse image representations to guide acoustic synthesis. However, we argue that this approach is insufficient to capture the intricate physical properties of the environment and may struggle with generalization across diverse scenes. In this work, we review the limitations of existing pipelines and address the research question: Can we leverage physical audio-visual associations to enhance neural acoustic synthesis? We introduce Physics-Integrated Audio-Visual Acoustic Synthesis (PI-AVAS or \pi-AVAS), a novel framework designed with two key objectives. i) Generalization: We develop a vision-guided audio simulation framework that leverages physics-based sound propagation. By explicitly modeling vision-grounded geometry and sound rays, our approach achieves robust performance across diverse visual environments. ii) Realism: While simulation-based approaches offer generalizability, they often compromise on realism. To mitigate this, we incorporate a second stage for data-centric refinement, where we propose a flow matching-based audio refinement model to narrow the gap between simulation and real-world audio-visual scenes. Extensive experiments demonstrate the effectiveness and robustness of our method. We achieve state-of-the-art performance on the RWAVS-Gen, RWAVS, and RAF datasets. Additionally, we show that our approach can be seamlessly integrated with existing methods to significantly improve their performance.
@inproceedings{liang2025pavas, author = {Liang, Susan and Huang, Chao and Tang, Yunlong and Zhang, Zeliang and Xu, Chenliang}, title = {p-AVAS: Can Physics-Integrated Audio-Visual Modeling Boost Neural Acoustic Synthesis?}, booktitle = {Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)}, year = {2025}, pages = {13942-13951}, } - ICCV Workshop
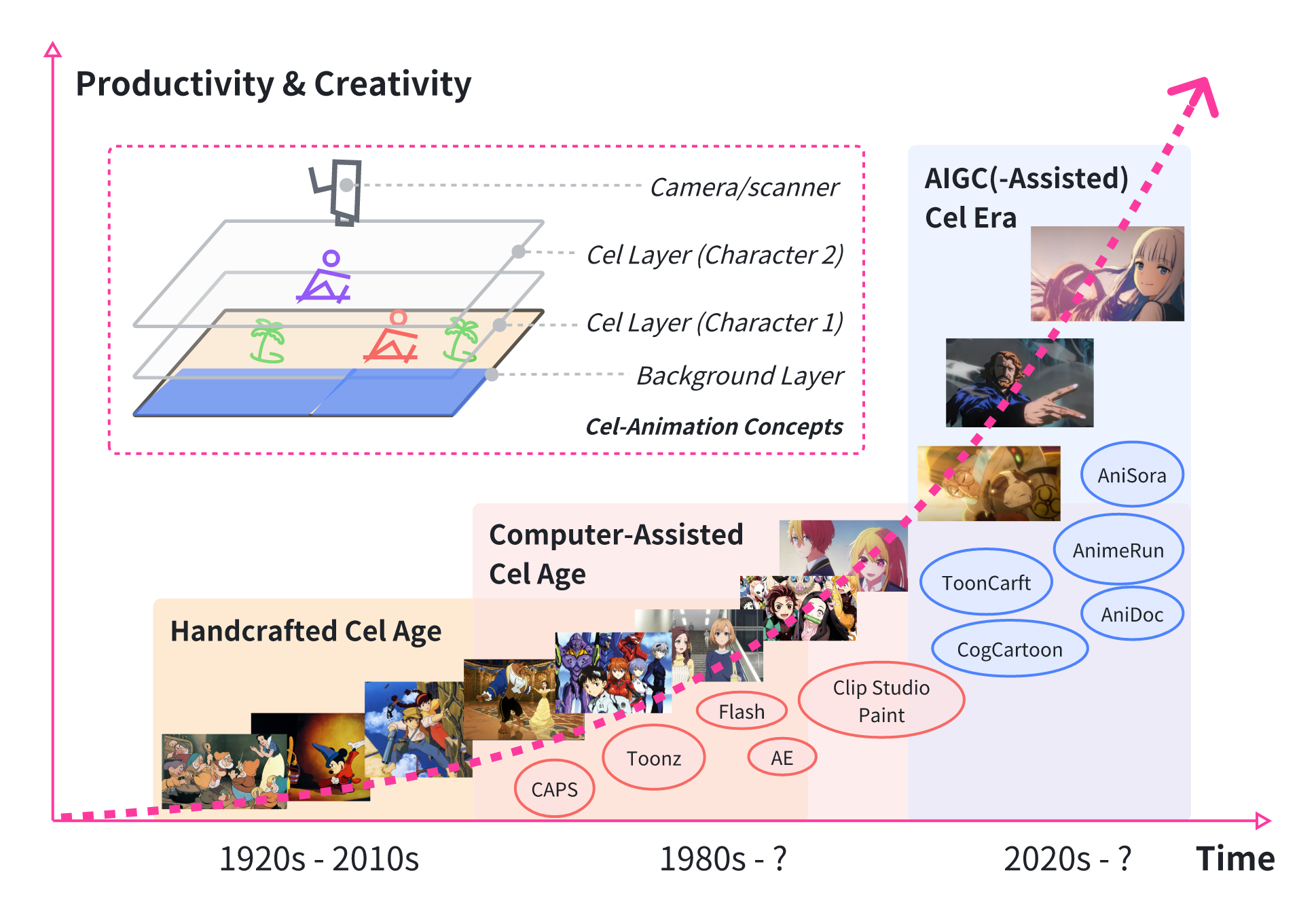 Yunlong Tang, Junjia Guo, Pinxin Liu, Zhiyuan Wang, Hang Hua, Jia-Xing Zhong, Yunzhong Xiao, Chao Huang, Luchuan Song, Susan Liang, and 7 more authorsProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) Workshops, 2025
Yunlong Tang, Junjia Guo, Pinxin Liu, Zhiyuan Wang, Hang Hua, Jia-Xing Zhong, Yunzhong Xiao, Chao Huang, Luchuan Song, Susan Liang, and 7 more authorsProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) Workshops, 2025@article{tang2025ai4anime, title = {Generative AI for Cel-Animation: A Survey 🔥🔥🔥}, author = {Tang, Yunlong and Guo, Junjia and Liu, Pinxin and Wang, Zhiyuan and Hua, Hang and Zhong, Jia-Xing and Xiao, Yunzhong and Huang, Chao and Song, Luchuan and Liang, Susan and Song, Yizhi and He, Liu and Bi, Jing and Feng, Mingqian and Li, Xinyang and Zhang, Zeliang and Xu, Chenliang}, journal = {Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) Workshops}, year = {2025}, pages = {3778-3791}, } - TCSVT
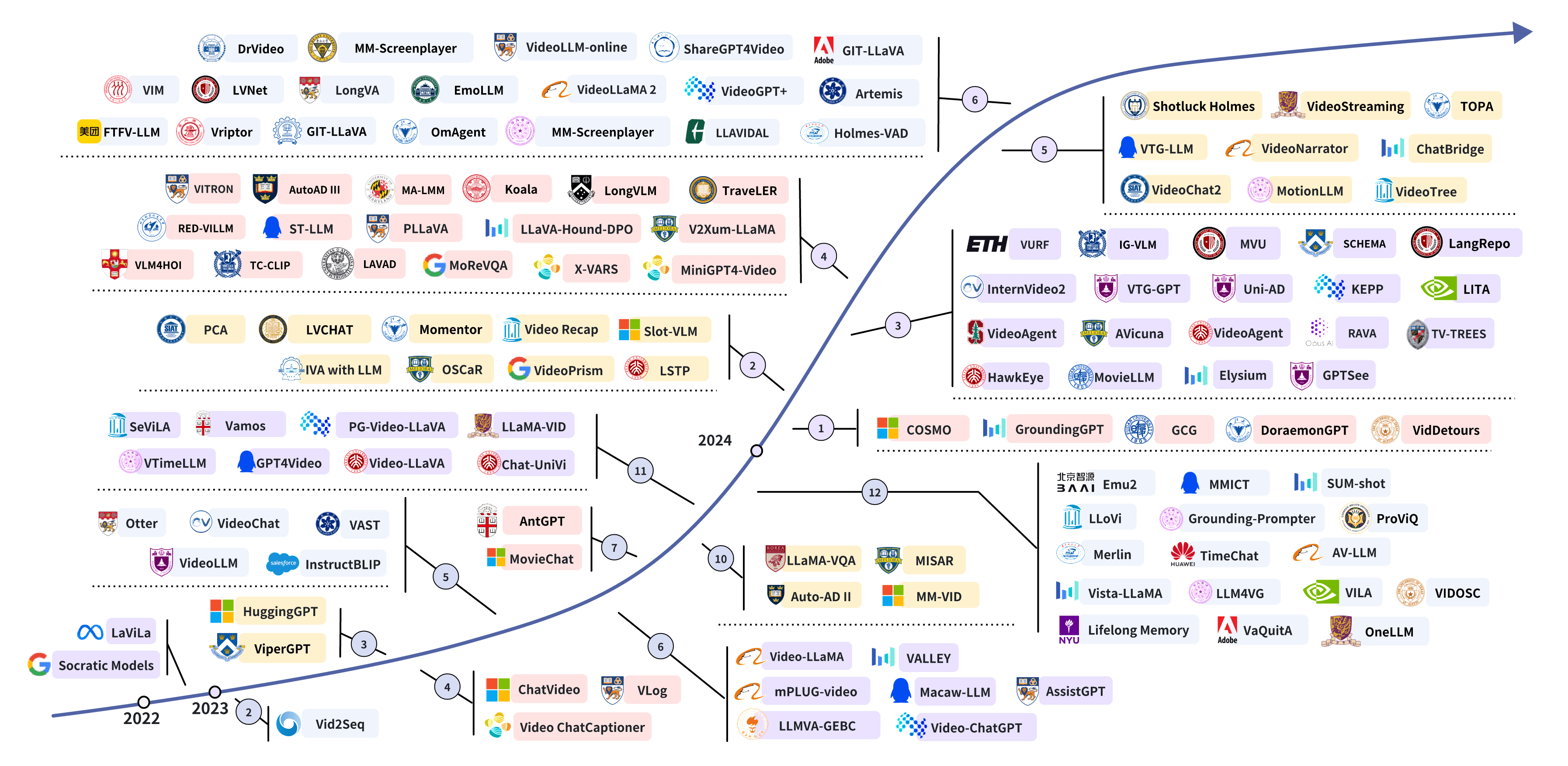 Yunlong Tang, Jing Bi, Siting Xu, Luchuan Song, Susan Liang, Teng Wang, Daoan Zhang, Jie An, Jingyang Lin, Rongyi Zhu, and 10 more authorsIEEE Transactions on Circuits and Systems for Video Technology (TCSVT), 2025
Yunlong Tang, Jing Bi, Siting Xu, Luchuan Song, Susan Liang, Teng Wang, Daoan Zhang, Jie An, Jingyang Lin, Rongyi Zhu, and 10 more authorsIEEE Transactions on Circuits and Systems for Video Technology (TCSVT), 2025With the burgeoning growth of online video platforms and the escalating volume of video content, the demand for proficient video understanding tools has intensified markedly. Given the remarkable capabilities of large language models (LLMs) in language and multimodal tasks, this survey provides a detailed overview of recent advancements in video understanding that harness the power of LLMs (Vid-LLMs). The emergent capabilities of Vid-LLMs are surprisingly advanced, particularly their ability for open-ended multi-granularity (general, temporal, and spatiotemporal) reasoning combined with commonsense knowledge, suggesting a promising path for future video understanding. We examine the unique characteristics and capabilities of Vid-LLMs, categorizing the approaches into three main types: Video Analyzer x LLM, Video Embedder x LLM, and (Analyzer + Embedder) x LLM. Furthermore, we identify five sub-types based on the functions of LLMs in Vid-LLMs: LLM as Summarizer, LLM as Manager, LLM as Text Decoder, LLM as Regressor, and LLM as Hidden Layer. Furthermore, this survey presents a comprehensive study of the tasks, datasets, benchmarks, and evaluation methodologies for Vid-LLMs. Additionally, it explores the expansive applications of Vid-LLMs across various domains, highlighting their remarkable scalability and versatility in real-world video understanding challenges. Finally, it summarizes the limitations of existing Vid-LLMs and outlines directions for future research. For more information, readers are recommended to visit the repository at https://github.com/yunlong10/awesome-llms-for-video-understanding.
@article{vidllmsurvey, title = {Video Understanding with Large Language Models: A Survey 🔥🔥🔥}, author = {Tang, Yunlong and Bi, Jing and Xu, Siting and Song, Luchuan and Liang, Susan and Wang, Teng and Zhang, Daoan and An, Jie and Lin, Jingyang and Zhu, Rongyi and Vosoughi, Ali and Huang, Chao and Zhang, Zeliang and Liu, Pinxin and Feng, Mingqian and Zheng, Feng and Zhang, Jianguo and Luo, Ping and Luo, Jiebo and Xu, Chenliang}, journal = {IEEE Transactions on Circuits and Systems for Video Technology (TCSVT)}, year = {2025}, publisher = {IEEE}, } - CVPR
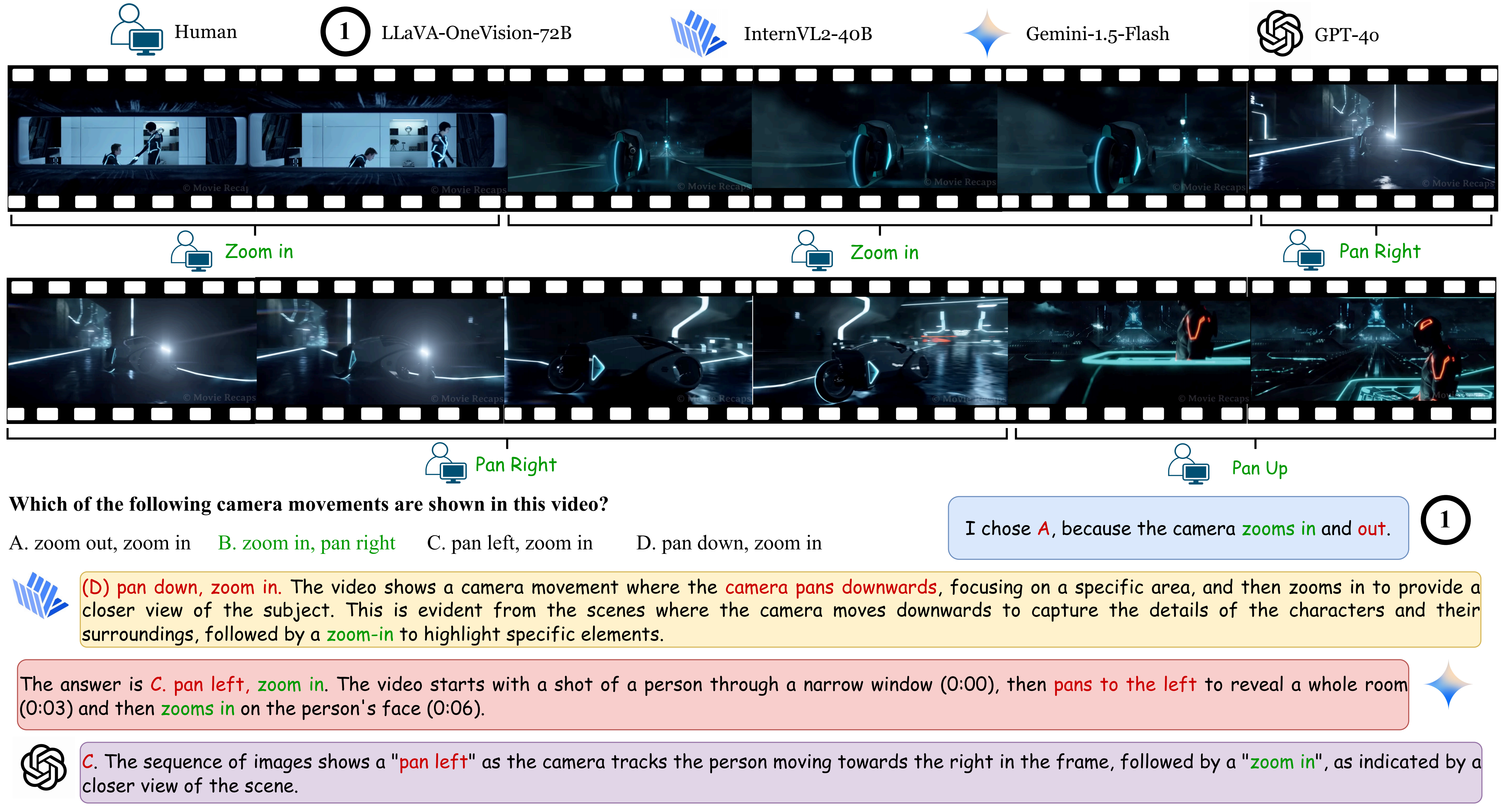 Yunlong Tang*, Junjia Guo*, Hang Hua, Susan Liang, Mingqian Feng, Xinyang Li, Rui Mao, Chao Huang, Jing Bi, Zeliang Zhang, and 2 more authorsIn Proceedings of the Computer Vision and Pattern Recognition Conference (CVPR), 2025
Yunlong Tang*, Junjia Guo*, Hang Hua, Susan Liang, Mingqian Feng, Xinyang Li, Rui Mao, Chao Huang, Jing Bi, Zeliang Zhang, and 2 more authorsIn Proceedings of the Computer Vision and Pattern Recognition Conference (CVPR), 2025@inproceedings{tang2024vidcompostion, title = {VidComposition: Can MLLMs Analyze Compositions in Compiled Videos?}, author = {Tang, Yunlong and Guo, Junjia and Hua, Hang and Liang, Susan and Feng, Mingqian and Li, Xinyang and Mao, Rui and Huang, Chao and Bi, Jing and Zhang, Zeliang and Fazli, Pooyan and Xu, Chenliang}, booktitle = {Proceedings of the Computer Vision and Pattern Recognition Conference (CVPR)}, year = {2025}, pages = {8490-8500}, } - CVPR
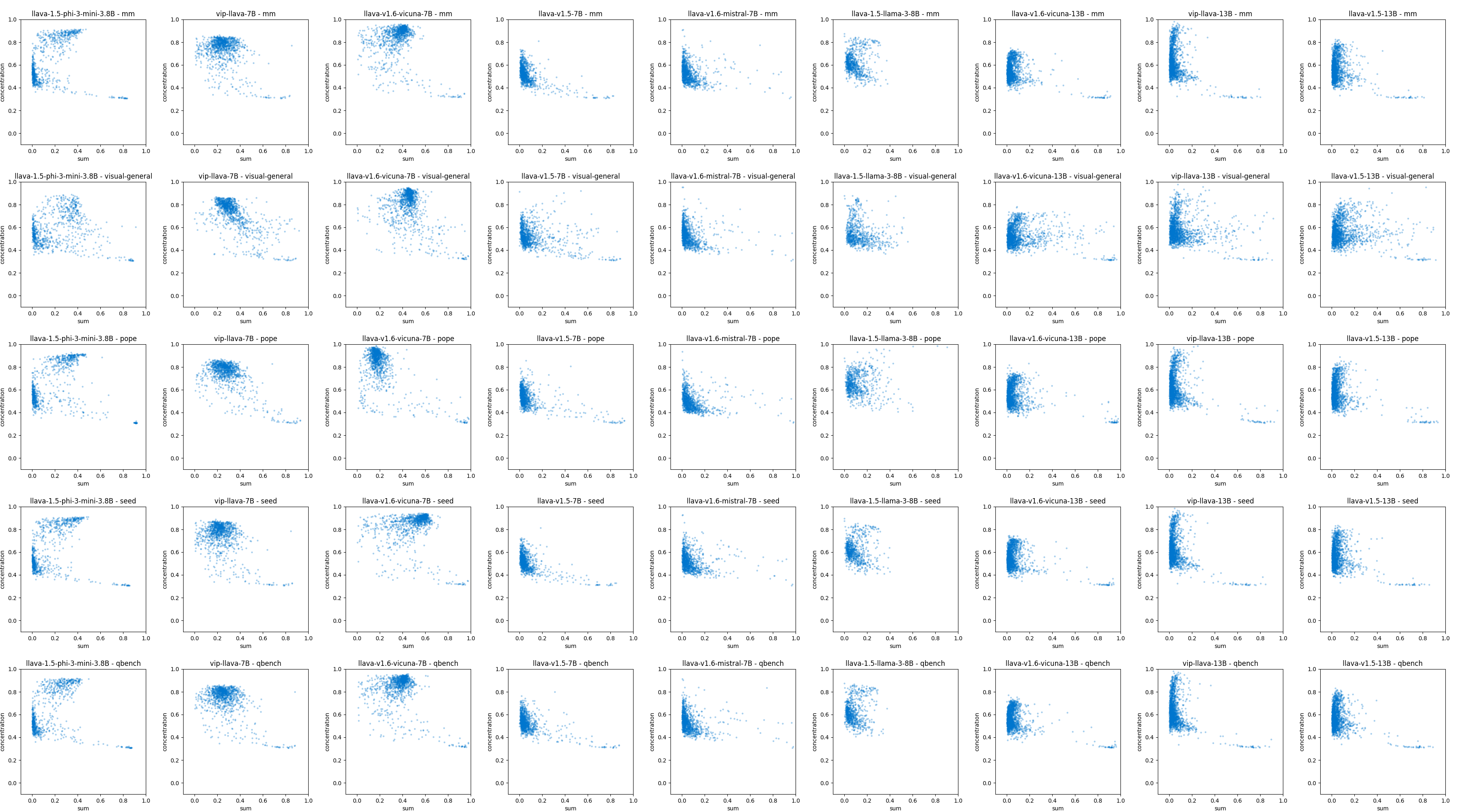 Jing Bi, Junjia Guo, Yunlong Tang, Lianggong Bruce Wen, Zhang Liu, and Chenliang XuIn Proceedings of the Computer Vision and Pattern Recognition Conference (CVPR), 2025
Jing Bi, Junjia Guo, Yunlong Tang, Lianggong Bruce Wen, Zhang Liu, and Chenliang XuIn Proceedings of the Computer Vision and Pattern Recognition Conference (CVPR), 2025@inproceedings{bi2024unveiling, title = {Unveiling Visual Perception in Language Models: An Attention Head Analysis Approach}, author = {Bi, Jing and Guo, Junjia and Tang, Yunlong and Wen, Lianggong Bruce and Liu, Zhang and Xu, Chenliang}, booktitle = {Proceedings of the Computer Vision and Pattern Recognition Conference (CVPR)}, year = {2025}, } - AAAI
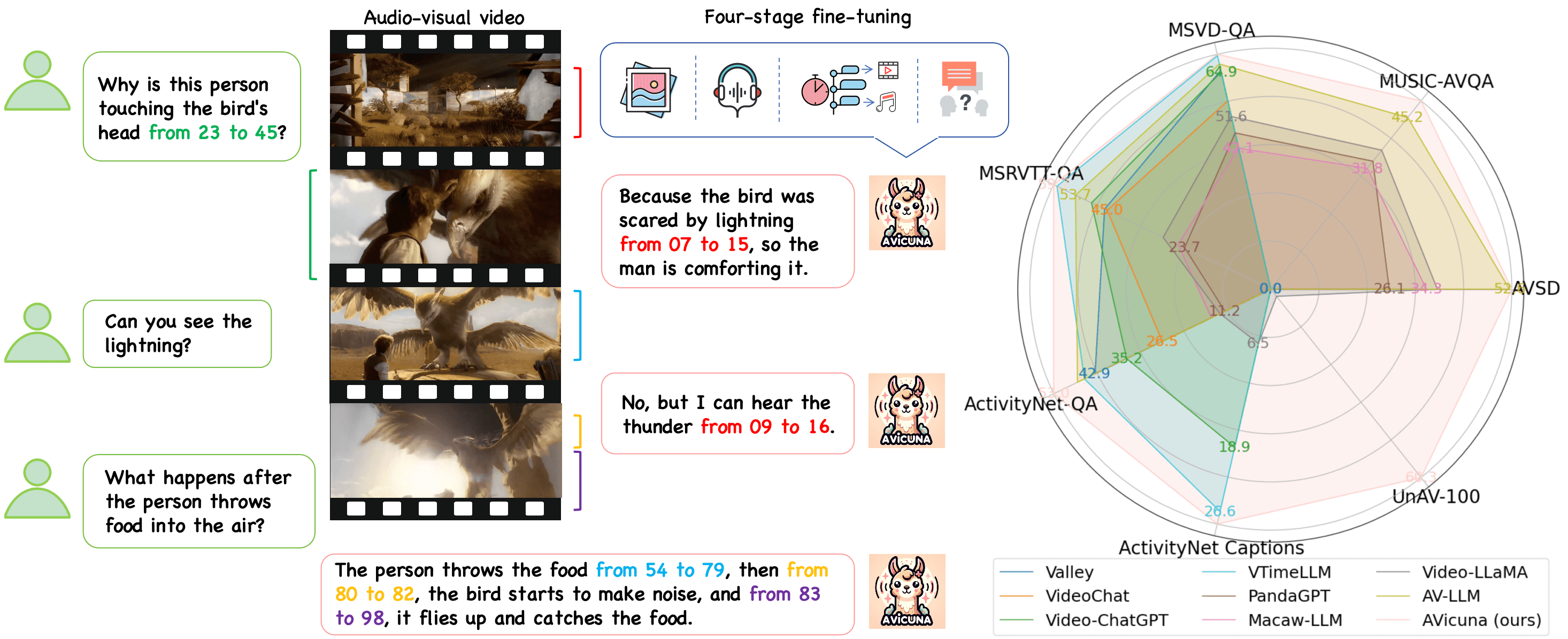 Yunlong Tang, Daiki Shimada, Jing Bi, Mingqian Feng, Hang Hua, and Chenliang Xu†In Proceedings of the AAAI Conference on Artificial Intelligence (AAAI), 2025
Yunlong Tang, Daiki Shimada, Jing Bi, Mingqian Feng, Hang Hua, and Chenliang Xu†In Proceedings of the AAAI Conference on Artificial Intelligence (AAAI), 2025Large language models (LLMs) have demonstrated remarkable capabilities in natural language and multimodal domains. By fine-tuning multimodal LLMs with temporal annotations from well-annotated datasets, e.g., dense video captioning datasets, their temporal understanding capacity in video-language tasks can be obtained. However, there is a notable lack of untrimmed audio-visual video datasets with precise temporal annotations for events. This deficiency hinders LLMs from learning the alignment between time, audio-visual events, and text tokens, thus impairing their ability to localize audio-visual events in videos temporally. To address this gap, we introduce PU-VALOR, a comprehensive audio-visual dataset comprising over 114,000 pseudo-untrimmed videos with detailed temporal annotations. PU-VALOR is derived from the large-scale but coarse-annotated audio-visual dataset VALOR, through a subtle method involving event-based video clustering, random temporal scaling, and permutation. By fine-tuning a multimodal LLM on PU-VALOR, we developed AVicuna, a model capable of aligning audio-visual events with temporal intervals and corresponding text tokens. AVicuna excels in temporal localization and time-aware dialogue capabilities. Our experiments demonstrate that AVicuna effectively handles temporal understanding in audio-visual videos and achieves state-of-the-art performance on open-ended video QA, audio-visual QA, and audio-visual event dense localization tasks.
@inproceedings{tang2024avicuna, title = {Empowering LLMs with Pseudo-Untrimmed Videos for Audio-Visual Temporal Understanding}, author = {Tang, Yunlong and Shimada, Daiki and Bi, Jing and Feng, Mingqian and Hua, Hang and Xu, Chenliang}, booktitle = {Proceedings of the AAAI Conference on Artificial Intelligence (AAAI)}, volume = {39}, number = {7}, pages = {7293-7301}, year = {2025}, doi = {10.1609/aaai.v39i7.32784}, } - AAAI
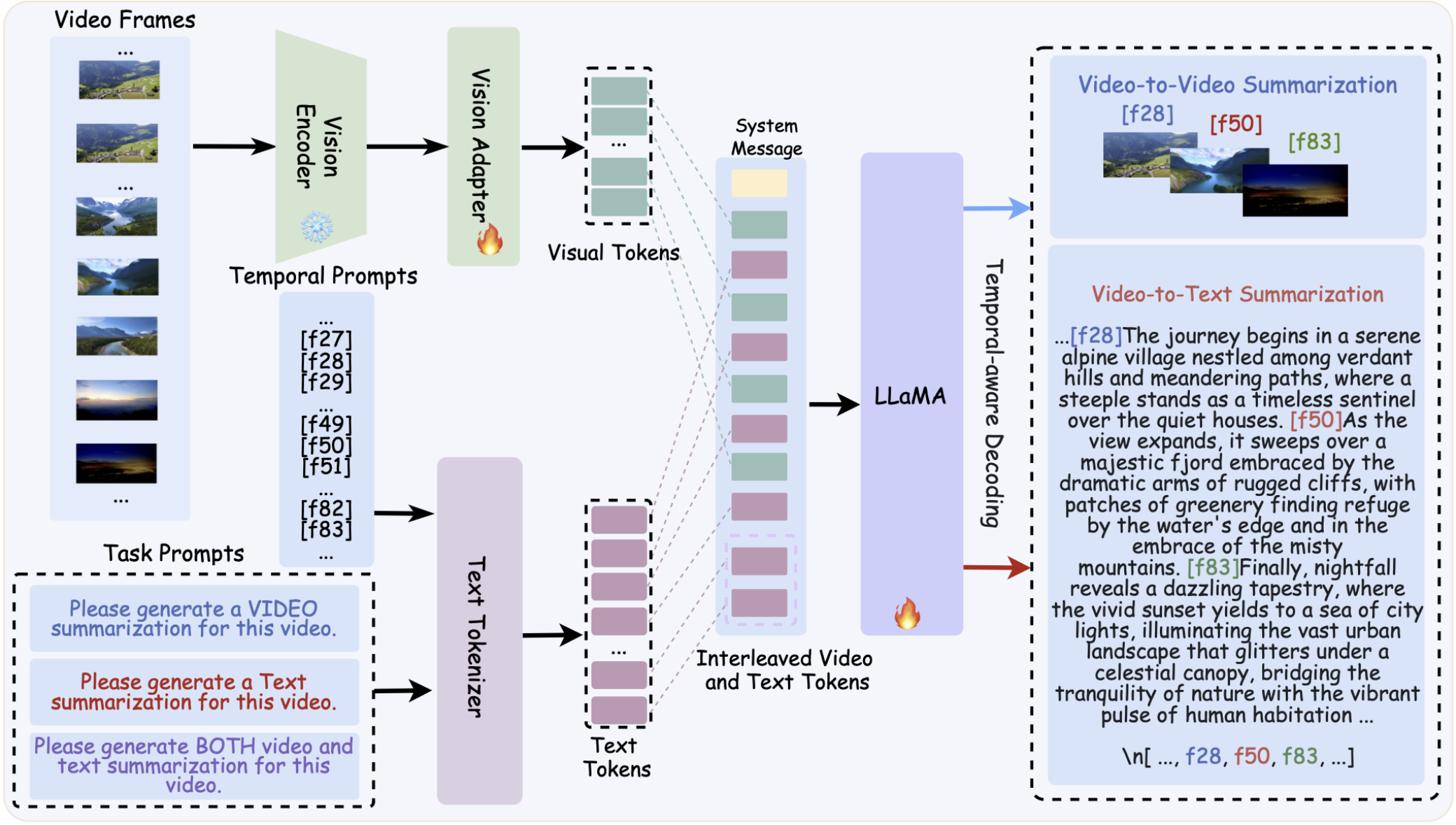 Hang Hua*, Yunlong Tang*, Chenliang Xu, and Jiebo Luo†In Proceedings of the AAAI Conference on Artificial Intelligence (AAAI), 2025
Hang Hua*, Yunlong Tang*, Chenliang Xu, and Jiebo Luo†In Proceedings of the AAAI Conference on Artificial Intelligence (AAAI), 2025@inproceedings{hua2024v2xum, title = {V2Xum-LLM: Cross-modal Video Summarization with Temporal Prompt Instruction Tuning}, author = {Hua, Hang and Tang, Yunlong and Xu, Chenliang and Luo, Jiebo}, booktitle = {Proceedings of the AAAI Conference on Artificial Intelligence (AAAI)}, volume = {39}, number = {4}, pages = {3599-3607}, year = {2025}, doi = {10.1609/aaai.v39i4.32374}, } - AAAI
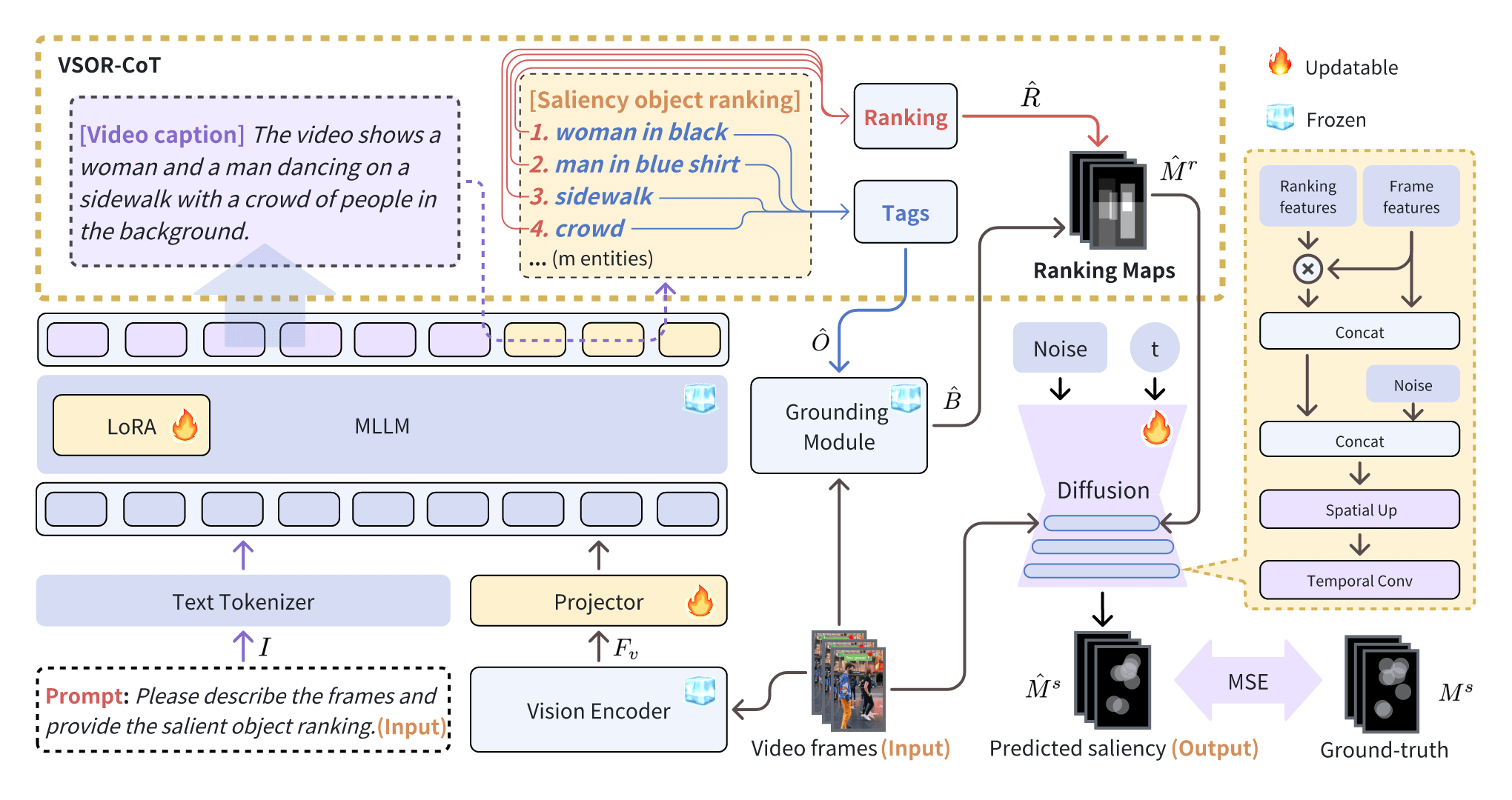 Yunlong Tang, Gen Zhan, Li Yang, Yiting Liao, and Chenliang Xu†In Proceedings of the AAAI Conference on Artificial Intelligence (AAAI), 2025
Yunlong Tang, Gen Zhan, Li Yang, Yiting Liao, and Chenliang Xu†In Proceedings of the AAAI Conference on Artificial Intelligence (AAAI), 2025Video saliency prediction aims to identify the regions in a video that attract human attention and gaze, driven by bottom-up features from the video and top-down processes like memory and cognition. Among these top-down influences, language plays a crucial role in guiding attention by shaping how visual information is interpreted. Existing methods primarily focus on modeling perceptual information while neglecting the reasoning process facilitated by language, where ranking cues are crucial outcomes of this process and practical guidance for saliency prediction. In this paper, we propose CaRDiff (Caption, Rank, and generate with Diffusion), a framework that imitates the process by integrating multimodal large language model (MLLM), a grounding module, and a diffusion model, to enhance video saliency prediction. Specifically, we introduce a novel prompting method VSOR-CoT (Video Salient Object Ranking Chain of Thought), which utilizes an MLLM with a grounding module to caption video content and infer salient objects along with their rankings and positions. This process derives ranking maps that can be sufficiently leveraged by the diffusion model to decode the saliency maps for the given video accurately. Extensive experiments show the effectiveness of VSOR-CoT in improving the performance of video saliency prediction. The proposed CaRDiff performs better than state-of-the-art models on the MVS dataset and demonstrates cross-dataset capabilities on the DHF1k dataset through zero-shot evaluation.
@inproceedings{tang2024cardiff, title = {CaRDiff: Video Salient Object Ranking Chain of Thought Reasoning for Saliency Prediction with Diffusion}, author = {Tang, Yunlong and Zhan, Gen and Yang, Li and Liao, Yiting and Xu, Chenliang}, booktitle = {Proceedings of the AAAI Conference on Artificial Intelligence (AAAI)}, year = {2025}, doi = {10.1609/aaai.v39i7.32785}, volume = {39}, number = {7}, pages = {7302-7310}, } - CVPR Workshop
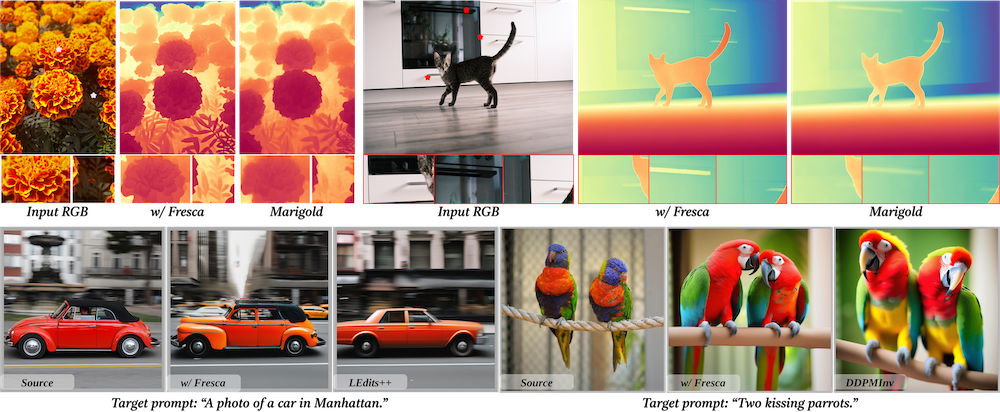 Chao Huang, Susan Liang, Yunlong Tang, Li Ma, Yapeng Tian, and Chenliang Xu†CVPR GMCV Workshop; arXiv preprint arXiv:2504.02154, 2025
Chao Huang, Susan Liang, Yunlong Tang, Li Ma, Yapeng Tian, and Chenliang Xu†CVPR GMCV Workshop; arXiv preprint arXiv:2504.02154, 2025Diffusion models offer impressive controllability for image tasks, primarily through noise predictions that encode task-specific information and classifier-free guidance enabling adjustable scaling. This scaling mechanism implicitly defines a “scaling space” whose potential for fine-grained semantic manipulation remains underexplored. We investigate this space, starting with inversion-based editing where the difference between conditional/unconditional noise predictions carries key semantic information. Our core contribution stems from a Fourier analysis of noise predictions, revealing that its low- and high-frequency components evolve differently throughout diffusion. Based on this insight, we introduce FreSca, a straightforward method that applies guidance scaling independently to different frequency bands in the Fourier domain. FreSca demonstrably enhances existing image editing methods without retraining. Excitingly, its effectiveness extends to image understanding tasks such as depth estimation, yielding quantitative gains across multiple datasets.
@article{huang2025fresca, title = {FreSca: Unveiling the Scaling Space in Diffusion Models}, author = {Huang, Chao and Liang, Susan and Tang, Yunlong and Ma, Li and Tian, Yapeng and Xu, Chenliang}, journal = {CVPR GMCV Workshop; arXiv preprint arXiv:2504.02154}, year = {2025}, } - CVPR Workshop
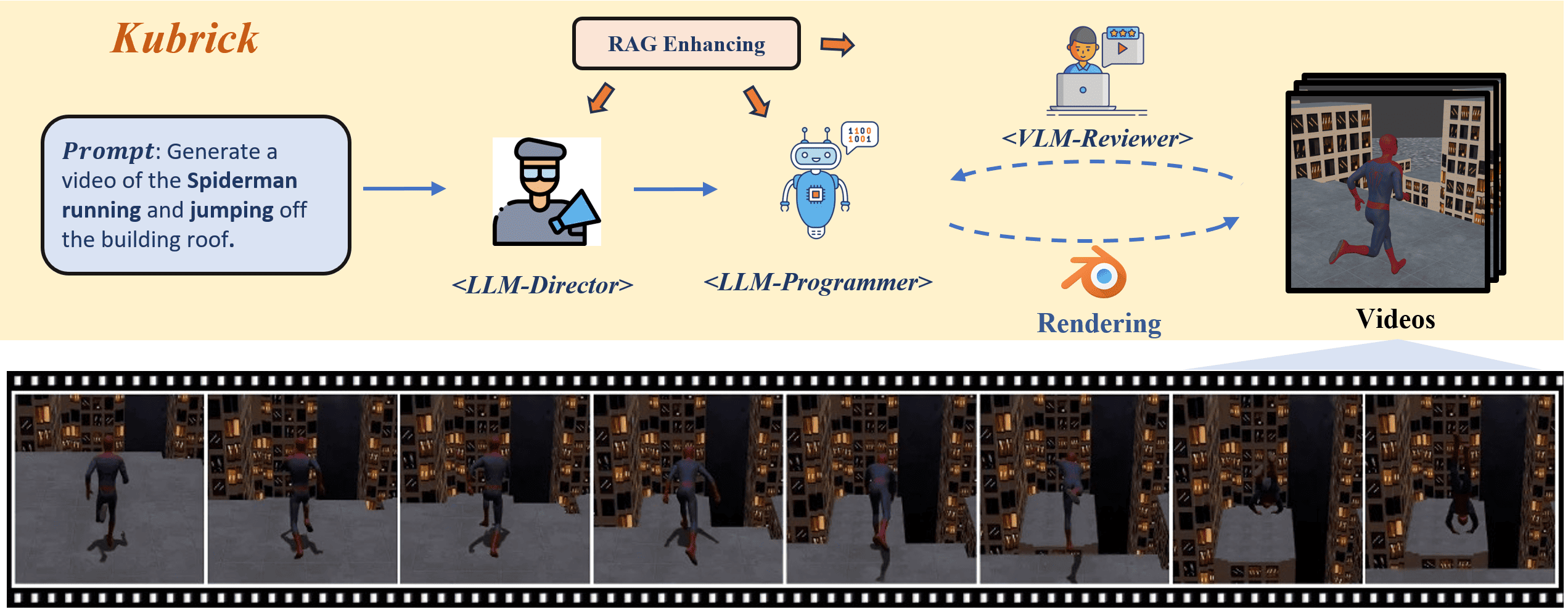 Liu He, Yizhi Song, Hejun Huang, Pinxin Liu, Yunlong Tang, Daniel Aliaga, and Xin ZhouCVPR AI4CC Workshop; arXiv preprint arXiv:2408.10453, 2025
Liu He, Yizhi Song, Hejun Huang, Pinxin Liu, Yunlong Tang, Daniel Aliaga, and Xin ZhouCVPR AI4CC Workshop; arXiv preprint arXiv:2408.10453, 2025Text-to-video generation has been dominated by diffusion-based or autoregressive models. These novel models provide plausible versatility, but are criticized for improper physical motion, shading and illumination, camera motion, and temporal consistency. The film industry relies on manually-edited Computer-Generated Imagery (CGI) using 3D modeling software. Human-directed 3D synthetic videos address these shortcomings, but require tight collaboration between movie makers and 3D rendering experts. We introduce an automatic synthetic video generation pipeline based on Vision Large Language Model (VLM) agent collaborations. Given a language description of a video, multiple VLM agents direct various processes of the generation pipeline. They cooperate to create Blender scripts which render a video following the given description. Augmented with Blender-based movie making knowledge, the Director agent decomposes the text-based video description into sub-processes. For each sub-process, the Programmer agent produces Python-based Blender scripts based on function composing and API calling. The Reviewer agent, with knowledge of video reviewing, character motion coordinates, and intermediate screenshots, provides feedback to the Programmer agent. The Programmer agent iteratively improves scripts to yield the best video outcome. Our generated videos show better quality than commercial video generation models in five metrics on video quality and instruction-following performance. Our framework outperforms other approaches in a user study on quality, consistency, and rationality.
@article{kubrick2025, title = {Kubrick: Multimodal Agent Collaborations for Synthetic Video Generation}, author = {He, Liu and Song, Yizhi and Huang, Hejun and Liu, Pinxin and Tang, Yunlong and Aliaga, Daniel and Zhou, Xin}, journal = {CVPR AI4CC Workshop; arXiv preprint arXiv:2408.10453}, year = {2025}, } - 3DV
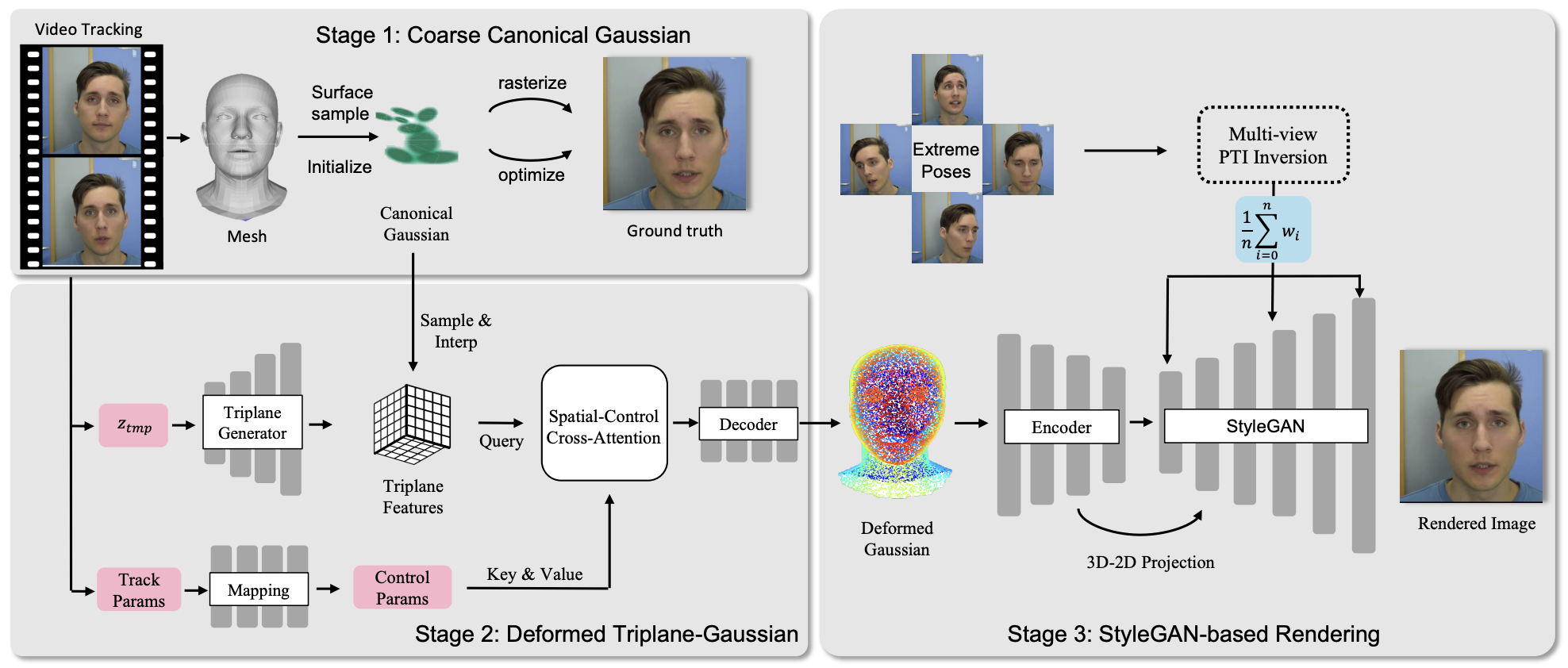 Pinxin Liu, Luchuan Song, Daoan Zhang, Hang Hua, Yunlong Tang, Huaijin Tu, Jiebo Luo, and Chenliang Xu†International Conference on 3D Vision (3DV), 2025
Pinxin Liu, Luchuan Song, Daoan Zhang, Hang Hua, Yunlong Tang, Huaijin Tu, Jiebo Luo, and Chenliang Xu†International Conference on 3D Vision (3DV), 2025Existing methods like Neural Radiation Fields (NeRF) and 3D Gaussian Splatting (3DGS) have made significant strides in facial attribute control such as facial animation and components editing, yet they struggle with fine-grained representation and scalability in dynamic head modeling. To address these limitations, we propose GaussianStyle, a novel framework that integrates the volumetric strengths of 3DGS with the powerful implicit representation of StyleGAN. The GaussianStyle preserves structural information, such as expressions and poses, using Gaussian points, while projecting the implicit volumetric representation into StyleGAN to capture high-frequency details and mitigate the over-smoothing commonly observed in neural texture rendering. Experimental outcomes indicate that our method achieves state-of-the-art performance in reenactment, novel view synthesis, and animation.
@article{liu2024emo, title = {GaussianStyle: Gaussian Head Avatar via StyleGAN}, author = {Liu, Pinxin and Song, Luchuan and Zhang, Daoan and Hua, Hang and Tang, Yunlong and Tu, Huaijin and Luo, Jiebo and Xu, Chenliang}, journal = {International Conference on 3D Vision (3DV)}, year = {2025}, } -
 Jing Bi, Susan Liang, Xiaofei Zhou, Pinxin Liu, Junjia Guo, Yunlong Tang, Luchuan Song, Chao Huang, Guangyu Sun, Jinxi He, and 8 more authorsarXiv preprint arXiv:2504.03151, 2025
Jing Bi, Susan Liang, Xiaofei Zhou, Pinxin Liu, Junjia Guo, Yunlong Tang, Luchuan Song, Chao Huang, Guangyu Sun, Jinxi He, and 8 more authorsarXiv preprint arXiv:2504.03151, 2025Reasoning is central to human intelligence, enabling structured problem-solving across diverse tasks. Recent advances in large language models (LLMs) have greatly enhanced their reasoning abilities in arithmetic, commonsense, and symbolic domains. However, effectively extending these capabilities into multimodal contexts-where models must integrate both visual and textual inputs-continues to be a significant challenge. Multimodal reasoning introduces complexities, such as handling conflicting information across modalities, which require models to adopt advanced interpretative strategies. Addressing these challenges involves not only sophisticated algorithms but also robust methodologies for evaluating reasoning accuracy and coherence. This paper offers a concise yet insightful overview of reasoning techniques in both textual and multimodal LLMs. Through a thorough and up-to-date comparison, we clearly formulate core reasoning challenges and opportunities, highlighting practical methods for post-training optimization and test-time inference. Our work provides valuable insights and guidance, bridging theoretical frameworks and practical implementations, and sets clear directions for future research.
-
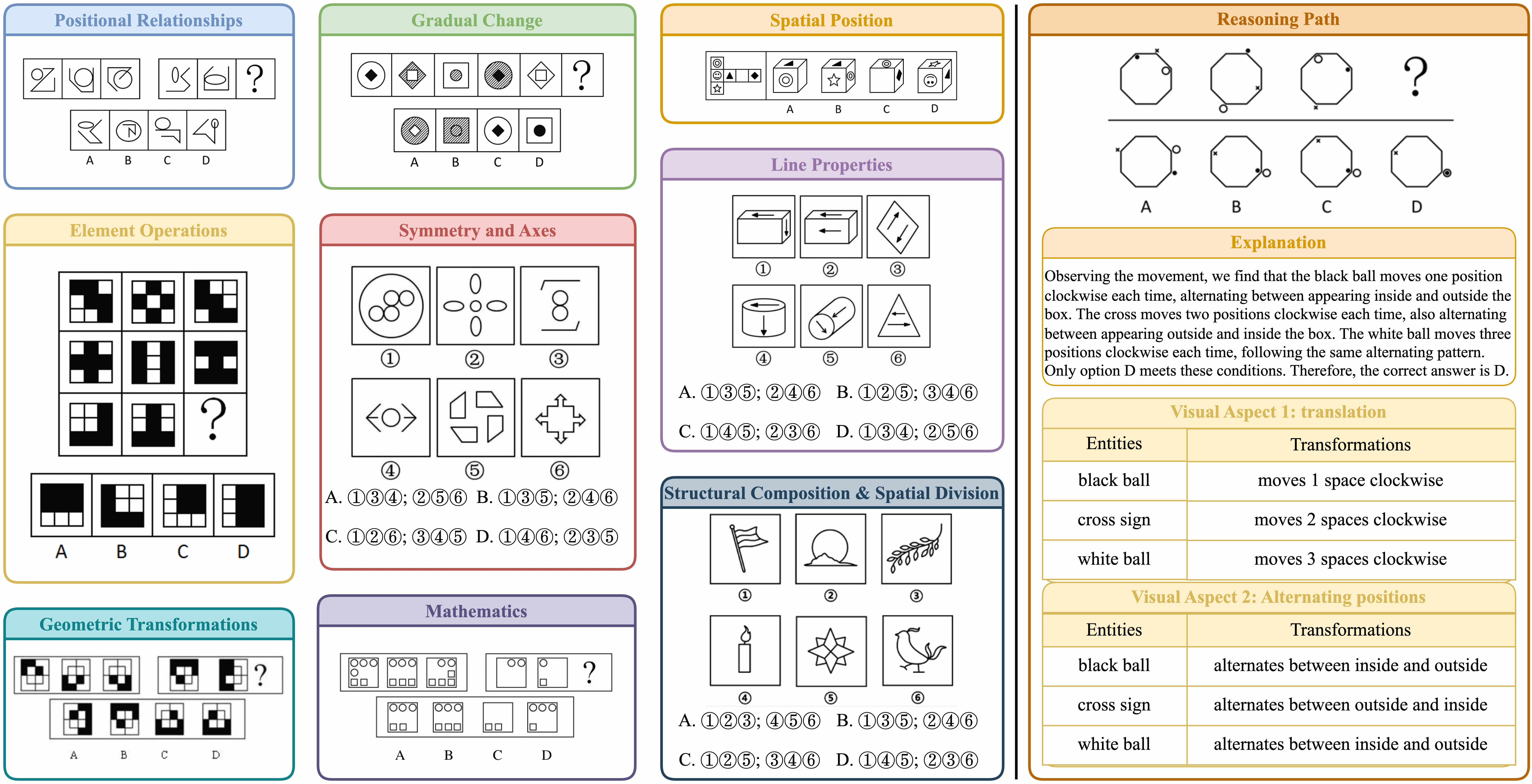 Jing Bi, Junjia Guo, Susan Liang, Guangyu Sun, Luchuan Song, Yunlong Tang, Jinxi He, Jiarui Wu, Ali Vosoughi, Chen Chen, and 1 more authorarXiv preprint arXiv:2503.11557, 2025
Jing Bi, Junjia Guo, Susan Liang, Guangyu Sun, Luchuan Song, Yunlong Tang, Jinxi He, Jiarui Wu, Ali Vosoughi, Chen Chen, and 1 more authorarXiv preprint arXiv:2503.11557, 2025Visual reasoning is central to human cognition, enabling individuals to interpret and abstractly understand their environment. Although recent Multimodal Large Language Models (MLLMs) have demonstrated impressive performance across language and vision-language tasks, existing benchmarks primarily measure recognition-based skills and inadequately assess true visual reasoning capabilities. To bridge this critical gap, we introduce VERIFY, a benchmark explicitly designed to isolate and rigorously evaluate the visual reasoning capabilities of state-of-the-art MLLMs. VERIFY compels models to reason primarily from visual information, providing minimal textual context to reduce reliance on domain-specific knowledge and linguistic biases. Each problem is accompanied by a human-annotated reasoning path, making it the first to provide in-depth evaluation of model decision-making processes. Additionally, we propose novel metrics that assess visual reasoning fidelity beyond mere accuracy, highlighting critical imbalances in current model reasoning patterns. Our comprehensive benchmarking of leading MLLMs uncovers significant limitations, underscoring the need for a balanced and holistic approach to both perception and reasoning. For more teaser and testing, visit our project page at https://verify-eqh.pages.dev/
@article{bi2025verify, title = {VERIFY: A Benchmark of Visual Explanation and Reasoning for Investigating Multimodal Reasoning Fidelity}, author = {Bi, Jing and Guo, Junjia and Liang, Susan and Sun, Guangyu and Song, Luchuan and Tang, Yunlong and He, Jinxi and Wu, Jiarui and Vosoughi, Ali and Chen, Chen and Xu, Chenliang}, journal = {arXiv preprint arXiv:2503.11557}, year = {2025}, }




































2024
- ACM MM
 Jing Bi, Yunlong Tang, Luchuan Song, Ali Vosoughi, Nguyen Nguyen, and Chenliang Xu†In Proceedings of the 32nd ACM International Conference on Multimedia (ACM MM), 2024
Jing Bi, Yunlong Tang, Luchuan Song, Ali Vosoughi, Nguyen Nguyen, and Chenliang Xu†In Proceedings of the 32nd ACM International Conference on Multimedia (ACM MM), 2024The rapid evolution of egocentric video analysis brings new insights into understanding human activities and intentions from a first-person perspective. Despite this progress, the fragmentation in tasks like action recognition, procedure learning, and moment retrieval, etc., coupled with inconsistent annotations and isolated model development, hinders a holistic interpretation of video content. In response, we introduce the EAGLE (Egocentric AGgregated Language-video Engine) model and the EAGLE-400K dataset to provide a unified framework that integrates various egocentric video understanding tasks. EAGLE-400K, the first large-scale instruction-tuning dataset tailored for egocentric video, features 400K diverse samples to enhance a broad spectrum task from activity recognition to procedure knowledge learning. Moreover, EAGLE, a strong video-based multimodal large language model (MLLM), is designed to effectively capture both spatial and temporal information. In addition, we propose a set of evaluation metrics designed to facilitate a thorough assessment of MLLM for egocentric video understanding. Our extensive experiments demonstrate EAGLE’s superior performance over existing models, highlighting its ability to balance task-specific understanding with comprehensive video interpretation. With EAGLE, we aim to pave the way for novel research opportunities and practical applications in real-world scenarios.
@inproceedings{bi2024eagle, title = {EAGLE: Egocentric AGgregated Language-video Engine}, author = {Bi, Jing and Tang, Yunlong and Song, Luchuan and Vosoughi, Ali and Nguyen, Nguyen and Xu, Chenliang}, booktitle = {Proceedings of the 32nd ACM International Conference on Multimedia (ACM MM)}, year = {2024}, pages = {1682--1691}, doi = {10.1145/3664647.3681618}, publisher = {Association for Computing Machinery}, } - ECCV Workshop
 Andrey Moskalenko, Alexey Bryncev, Dmitry Vatolin, Radu Timofte, Gen Zhan, Li Yang, Yunlong Tang, Yiting Liao, Jiongzhi Lin, Baitao Huang, and 23 more authorsIn Proceedings of the European Conference on Computer Vision (ECCV) Workshops, 2024
Andrey Moskalenko, Alexey Bryncev, Dmitry Vatolin, Radu Timofte, Gen Zhan, Li Yang, Yunlong Tang, Yiting Liao, Jiongzhi Lin, Baitao Huang, and 23 more authorsIn Proceedings of the European Conference on Computer Vision (ECCV) Workshops, 2024@inproceedings{moskalenko2024aim, title = {AIM 2024 Challenge on Video Saliency Prediction: Methods and Results}, author = {Moskalenko, Andrey and Bryncev, Alexey and Vatolin, Dmitry and Timofte, Radu and Zhan, Gen and Yang, Li and Tang, Yunlong and Liao, Yiting and Lin, Jiongzhi and Huang, Baitao and Moradi, Morteza and Moradi, Mohammad and Rundo, Francesco and Spampinato, Concetto and Borji, Ali and Palazzo, Simone and Zhu, Yuxin and Sun, Yinan and Duan, Huiyu and Cao, Yuqin and Jia, Ziheng and Hu, Qiang and Min, Xiongkuo and Zhai, Guangtao and Fang, Hao and Cong, Runmin and Lu, Xiankai and Zhou, Xiaofei and Zhang, Wei and Zhao, Chunyu and Mu, Wentao and Deng, Tao and Tavakoli, Hamed R}, booktitle = {Proceedings of the European Conference on Computer Vision (ECCV) Workshops}, year = {2024}, } -
 Hang Hua*, Yunlong Tang*, Ziyun Zeng*, Liangliang Cao, Zhengyuan Yang, Hangfeng He, Chenliang Xu, and Jiebo LuoarXiv preprint arXiv:2410.09733, 2024
Hang Hua*, Yunlong Tang*, Ziyun Zeng*, Liangliang Cao, Zhengyuan Yang, Hangfeng He, Chenliang Xu, and Jiebo LuoarXiv preprint arXiv:2410.09733, 2024The advent of large Vision-Language Models (VLMs) has significantly advanced multimodal understanding, enabling more sophisticated and accurate integration of visual and textual information across various tasks, including image and video captioning, visual question answering, and cross-modal retrieval. Despite VLMs’ superior capabilities, researchers lack a comprehensive understanding of their compositionality – the ability to understand and produce novel combinations of known visual and textual components. Prior benchmarks provide only a relatively rough compositionality evaluation from the perspectives of objects, relations, and attributes while neglecting deeper reasoning about object interactions, counting, and complex compositions. However, compositionality is a critical ability that facilitates coherent reasoning and understanding across modalities for VLMs. To address this limitation, we propose MMCOMPOSITION, a novel human-annotated benchmark for comprehensively and accurately evaluating VLMs’ compositionality. Our proposed benchmark serves as a complement to these earlier works. With MMCOMPOSITION, we can quantify and explore the compositionality of the mainstream VLMs. Surprisingly, we find GPT-4o’s compositionality inferior to the best open-source model, and we analyze the underlying reasons. Our experimental analysis reveals the limitations of VLMs in fine-grained compositional perception and reasoning, and points to areas for improvement in VLM design and training. Resources available at: https://hanghuacs.github.io/MMComposition/
@article{hua2024mmcomposition, title = {MMCOMPOSITION: Revisiting the Compositionality of Pre-trained Vision-Language Models}, author = {Hua, Hang and Tang, Yunlong and Zeng, Ziyun and Cao, Liangliang and Yang, Zhengyuan and He, Hangfeng and Xu, Chenliang and Luo, Jiebo}, journal = {arXiv preprint arXiv:2410.09733}, year = {2024}, } -
 Mingqian Feng, Yunlong Tang, Zeliang Zhang, and Chenliang Xu†arXiv preprint arXiv:2406.12663, 2024
Mingqian Feng, Yunlong Tang, Zeliang Zhang, and Chenliang Xu†arXiv preprint arXiv:2406.12663, 2024Large Vision-Language Models (LVLMs) excel in integrating visual and linguistic contexts to produce detailed content, facilitating applications such as image captioning. However, using LVLMs to generate descriptions often faces the challenge of object hallucination (OH), where the output text misrepresents actual objects in the input image. While previous studies attribute the occurrence of OH to the inclusion of more details, our study finds technical flaws in existing metrics, leading to unreliable evaluations of models and conclusions about OH. This has sparked a debate on the question: Do more details always introduce more hallucinations in LVLM-based image captioning? In this paper, we address this debate by proposing a novel decoding strategy, Differentiated Beam Decoding (DBD), along with a reliable new set of evaluation metrics: CLIP-Precision, CLIP-Recall, and CLIP-F1. DBD decodes the wealth of information hidden in visual input into distinct language representations called unit facts in parallel. This decoding is achieved via a well-designed differential score that guides the parallel search and candidate screening. The selected unit facts are then aggregated to generate the final caption. Our proposed metrics evaluate the comprehensiveness and accuracy of image captions by comparing the embedding groups of ground-truth image regions and generated text partitions. Extensive experiments on the Visual Genome dataset validate the effectiveness of our approach, demonstrating that it produces detailed descriptions while maintaining low hallucination levels.
@article{feng2024more, title = {Do More Details Always Introduce More Hallucinations in LVLM-based Image Captioning?}, author = {Feng, Mingqian and Tang, Yunlong and Zhang, Zeliang and Xu, Chenliang}, journal = {arXiv preprint arXiv:2406.12663}, year = {2024}, } -
 Chao Huang, Susan Liang, Yunlong Tang, Yapeng Tian, Anurag Kumar, and Chenliang Xu†arXiv preprint arXiv:2410.24151, 2024
Chao Huang, Susan Liang, Yunlong Tang, Yapeng Tian, Anurag Kumar, and Chenliang Xu†arXiv preprint arXiv:2410.24151, 2024Text-guided diffusion models have revolutionized generative tasks by producing high-fidelity content from text descriptions. They have also enabled an editing paradigm where concepts can be replaced through text conditioning (e.g., a dog to a tiger). In this work, we explore a novel approach: instead of replacing a concept, can we enhance or suppress the concept itself? Through an empirical study, we identify a trend where concepts can be decomposed in text-guided diffusion models. Leveraging this insight, we introduce ScalingConcept, a simple yet effective method to scale decomposed concepts up or down in real input without introducing new elements. To systematically evaluate our approach, we present the WeakConcept-10 dataset, where concepts are imperfect and need to be enhanced. More importantly, ScalingConcept enables a variety of novel zero-shot applications across image and audio domains, including tasks such as canonical pose generation and generative sound highlighting or removal.
@article{huang2024scalingconcept, title = {Scaling Concept with Text-Guided Diffusion Models}, author = {Huang, Chao and Liang, Susan and Tang, Yunlong and Tian, Yapeng and Kumar, Anurag and Xu, Chenliang}, journal = {arXiv preprint arXiv:2410.24151}, year = {2024}, }








2023
- CVPR Workshop
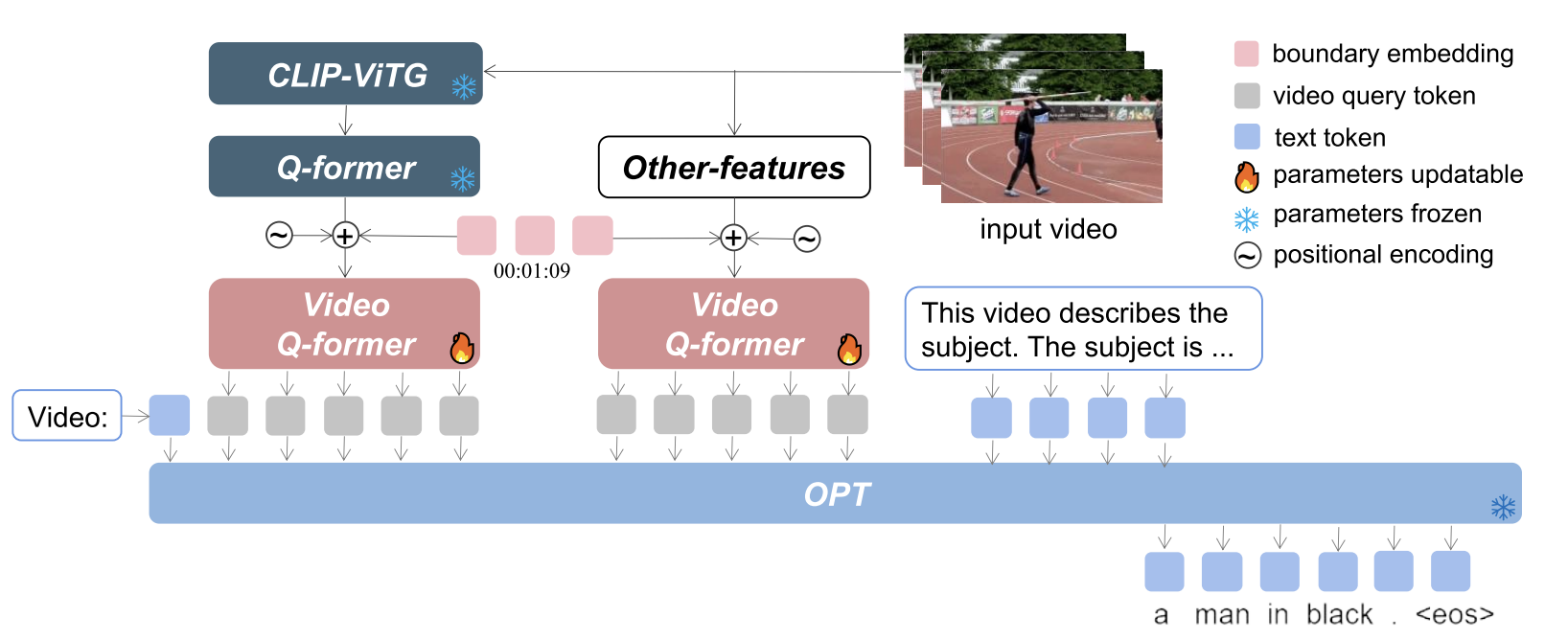 Yunlong Tang, Jinrui Zhang, Xiangchen Wang, Teng Wang, and Feng Zheng†CVPR LOVEU Workshop; arXiv preprint arXiv:2306.10354, 2023
Yunlong Tang, Jinrui Zhang, Xiangchen Wang, Teng Wang, and Feng Zheng†CVPR LOVEU Workshop; arXiv preprint arXiv:2306.10354, 2023Our winning entry for the CVPR 2023 Generic Event Boundary Captioning (GEBC) competition is detailed in this paper. Unlike conventional video captioning tasks, GEBC demands that the captioning model possess an understanding of immediate changes in status around the designated video boundary, making it a difficult task. This paper proposes an effective model LLMVA-GEBC (Large Language Model with Video Adapter for Generic Event Boundary Captioning): (1) We utilize a pretrained LLM for generating human-like captions with high quality. (2) To adapt the model to the GEBC task, we take the video Q-former as an adapter and train it with the frozen visual feature extractors and LLM. Our proposed method achieved a 76.14 score on the test set and won the first place in the challenge. Our code is available at https://github.com/zjr2000/LLMVA-GEBC.
@article{tang2023llmva, title = {LLMVA-GEBC: Large Language Model with Video Adapter for Generic Event Boundary Captioning}, author = {Tang, Yunlong and Zhang, Jinrui and Wang, Xiangchen and Wang, Teng and Zheng, Feng}, journal = {CVPR LOVEU Workshop; arXiv preprint arXiv:2306.10354}, year = {2023}, } - ICMC
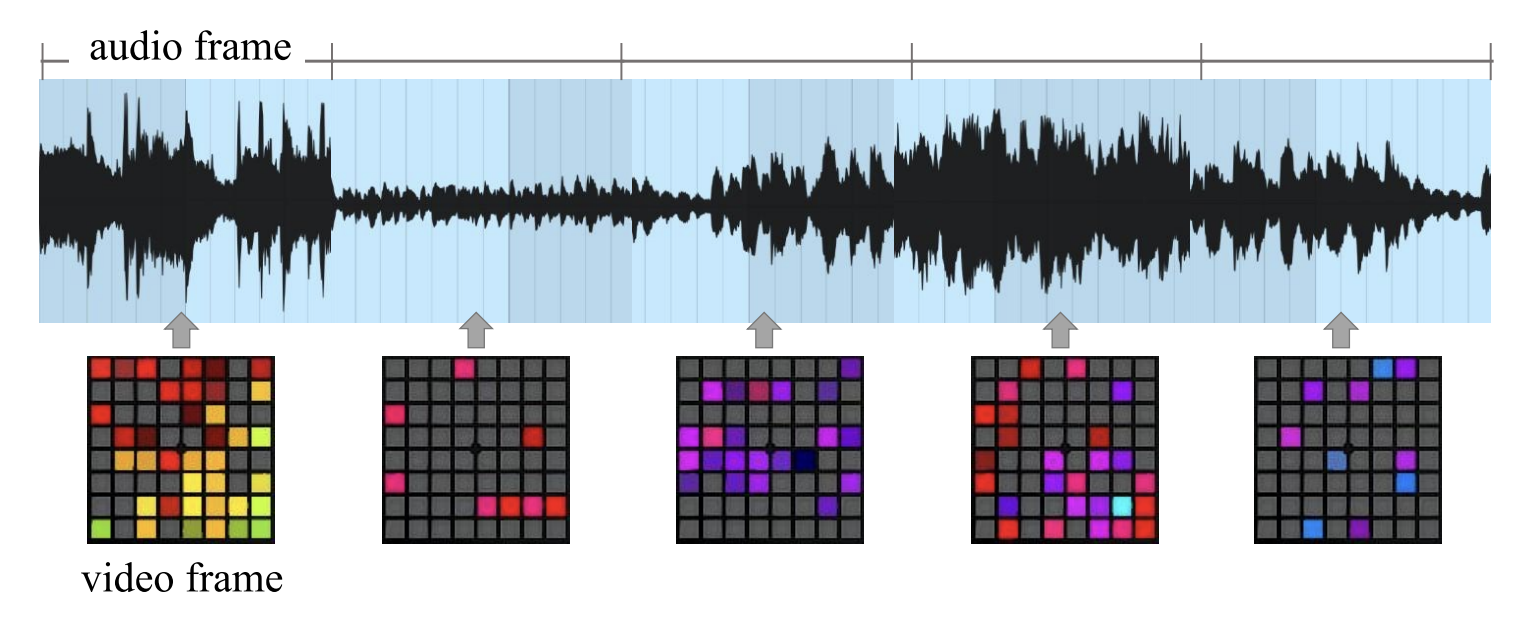 Siting Xu*, Yunlong Tang*, and Feng Zheng†In Proceedings of the International Computer Music Conference (ICMC), 2023
Siting Xu*, Yunlong Tang*, and Feng Zheng†In Proceedings of the International Computer Music Conference (ICMC), 2023Launchpad is a popular music instrument for live performance and music production. In this paper, we propose LaunchpadGPT, a language model that can generate music visualization designs for Launchpad. We train the model on a large-scale dataset of music visualization designs and demonstrate its effectiveness in generating diverse and creative designs. We also develop a web-based platform that allows users to interact with the model and generate music visualization designs in real-time. Our code is available at https://github.com/yunlong10/LaunchpadGPT.
@inproceedings{xu2023launchpadgpt, title = {LaunchpadGPT: Language Model as Music Visualization Designer on Launchpad}, author = {Xu, Siting and Tang, Yunlong and Zheng, Feng}, booktitle = {Proceedings of the International Computer Music Conference (ICMC)}, year = {2023}, pages = {213-217}, } -
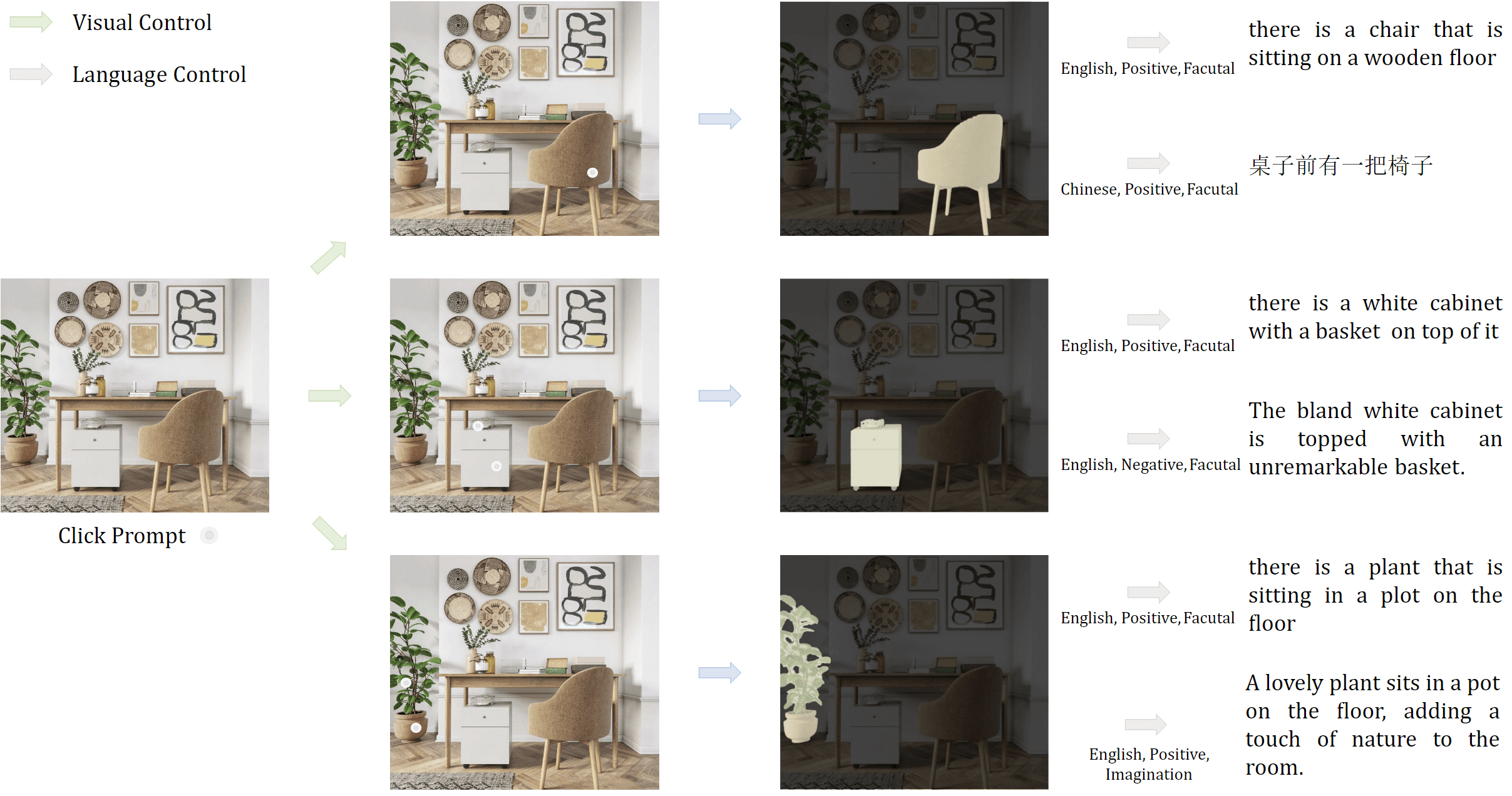 Teng Wang*, Jinrui Zhang*, Junjie Fei*, Hao Zheng, Yunlong Tang, Zhe Li, Mingqi Gao, and Shanshan ZhaoarXiv preprint arXiv:2305.02677, 2023
Teng Wang*, Jinrui Zhang*, Junjie Fei*, Hao Zheng, Yunlong Tang, Zhe Li, Mingqi Gao, and Shanshan ZhaoarXiv preprint arXiv:2305.02677, 2023Controllable image captioning is an emerging multimodal topic that aims to describe the image with natural language following human purpose, e.g., looking at the specified regions or telling in a particular text style. State-of-the-art methods are trained on annotated pairs of input controls and output captions. However, the scarcity of such well-annotated multimodal data largely limits their usability and scalability for interactive AI systems. Leveraging unimodal instruction-following foundation models is a promising alternative that benefits from broader sources of data. In this paper, we present Caption AnyThing (CAT), a foundation model augmented image captioning framework supporting a wide range of multimodel controls: 1) visual controls, including points, boxes, and trajectories; 2) language controls, such as sentiment, length, language, and factuality. Powered by Segment Anything Model (SAM) and ChatGPT, we unify the visual and language prompts into a modularized framework, enabling the flexible combination between different controls. Extensive case studies demonstrate the user intention alignment capabilities of our framework, shedding light on effective user interaction modeling in vision-language applications. Our code is publicly available at https://github.com/ttengwang/caption-anything
@article{wang2023caption, title = {Caption Anything: Interactive Image Description with Diverse Multimodal Controls}, author = {Wang, Teng and Zhang, Jinrui and Fei, Junjie and Zheng, Hao and Tang, Yunlong and Li, Zhe and Gao, Mingqi and Zhao, Shanshan}, journal = {arXiv preprint arXiv:2305.02677}, year = {2023}, }






2022
- ACCV
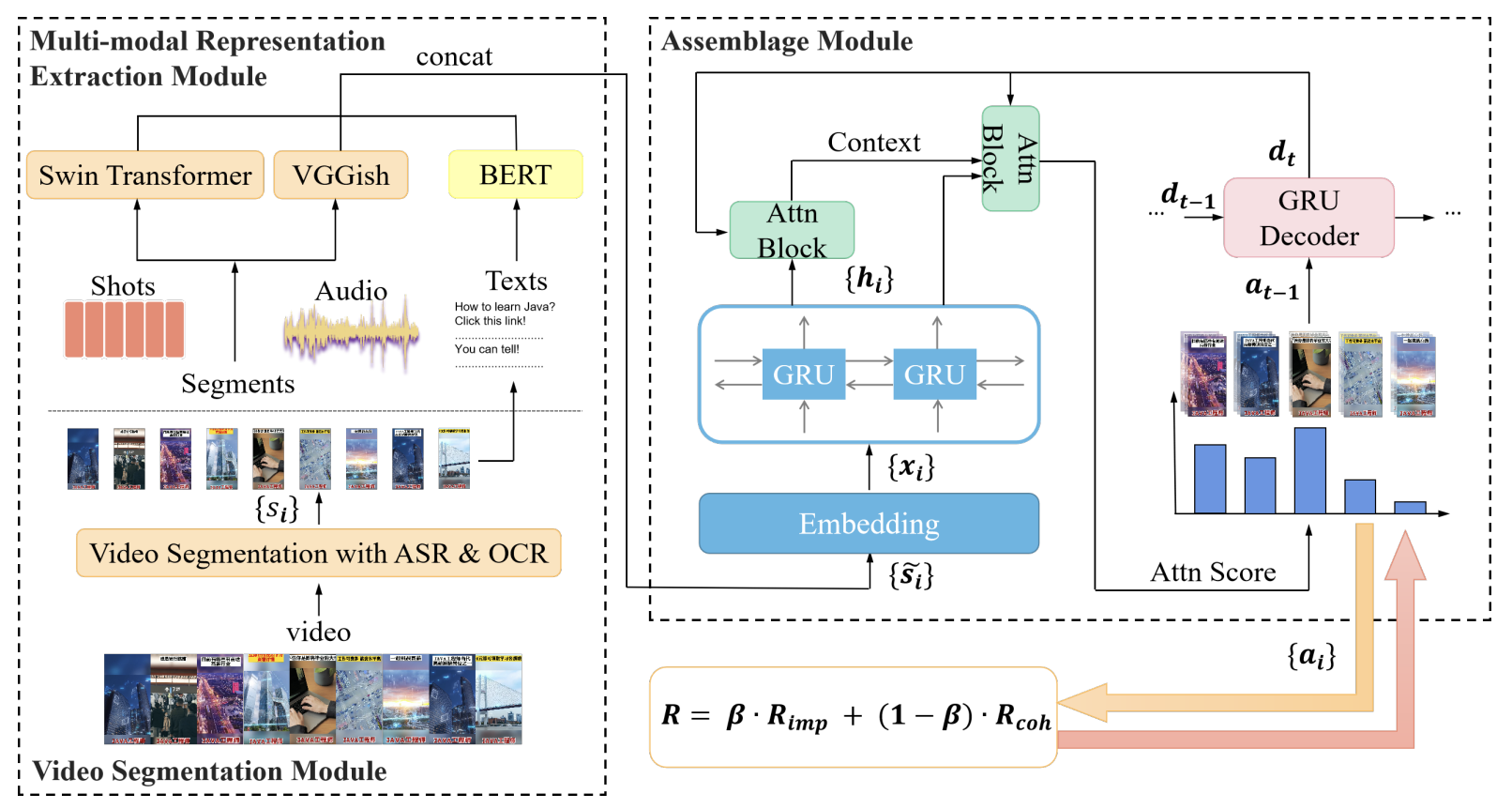 Yunlong Tang, Siting Xu, Teng Wang, Qin Lin, Qinglin Lu, and Feng Zheng†In Proceedings of the Asian Conference on Computer Vision (ACCV), 2022
Yunlong Tang, Siting Xu, Teng Wang, Qin Lin, Qinglin Lu, and Feng Zheng†In Proceedings of the Asian Conference on Computer Vision (ACCV), 2022Advertisement video editing aims to automatically edit advertising videos into shorter videos while retaining coherent content and crucial information conveyed by advertisers. It mainly contains two stages: video segmentation and segment assemblage. The existing method performs well at video segmentation stages but suffers from the problems of dependencies on extra cumbersome models and poor performance at the segment assemblage stage. To address these problems, we propose M-SAN (Multi-modal Segment Assemblage Network) which can perform efficient and coherent segment assemblage task end-to-end. It utilizes multi-modal representation extracted from the segments and follows the Encoder-Decoder Ptr-Net framework with the Attention mechanism. Importance-coherence reward is designed for training M-SAN. We experiment on the Ads-1k dataset with 1000+ videos under rich ad scenarios collected from advertisers. To evaluate the methods, we propose a unified metric, Imp-Coh@Time, which comprehensively assesses the importance, coherence, and duration of the outputs at the same time. Experimental results show that our method achieves better performance than random selection and the previous method on the metric. Ablation experiments further verify that multi-modal representation and importance-coherence reward significantly improve the performance. Ads-1k dataset is available at: https://github.com/yunlong10/Ads-1k.
@inproceedings{Tang_2022_ACCV, author = {Tang, Yunlong and Xu, Siting and Wang, Teng and Lin, Qin and Lu, Qinglin and Zheng, Feng}, title = {Multi-modal Segment Assemblage Network for Ad Video Editing with Importance-Coherence Reward}, booktitle = {Proceedings of the Asian Conference on Computer Vision (ACCV)}, year = {2022}, pages = {3519-3535}, }

